问题
日常我们经常遇到表头是合并的单元格,如左侧表头,或者上测表头都是合并过的,而我们想读取使用pandas读取的excel后,每列都进行对应回原来的数据的结构,那么这时就需要进行填充了,因为读取后,只有合并的单元格的第一行或第一列是有值的,其它都是nan,我们需要用前向填充的方法,ffill()
示例如图:
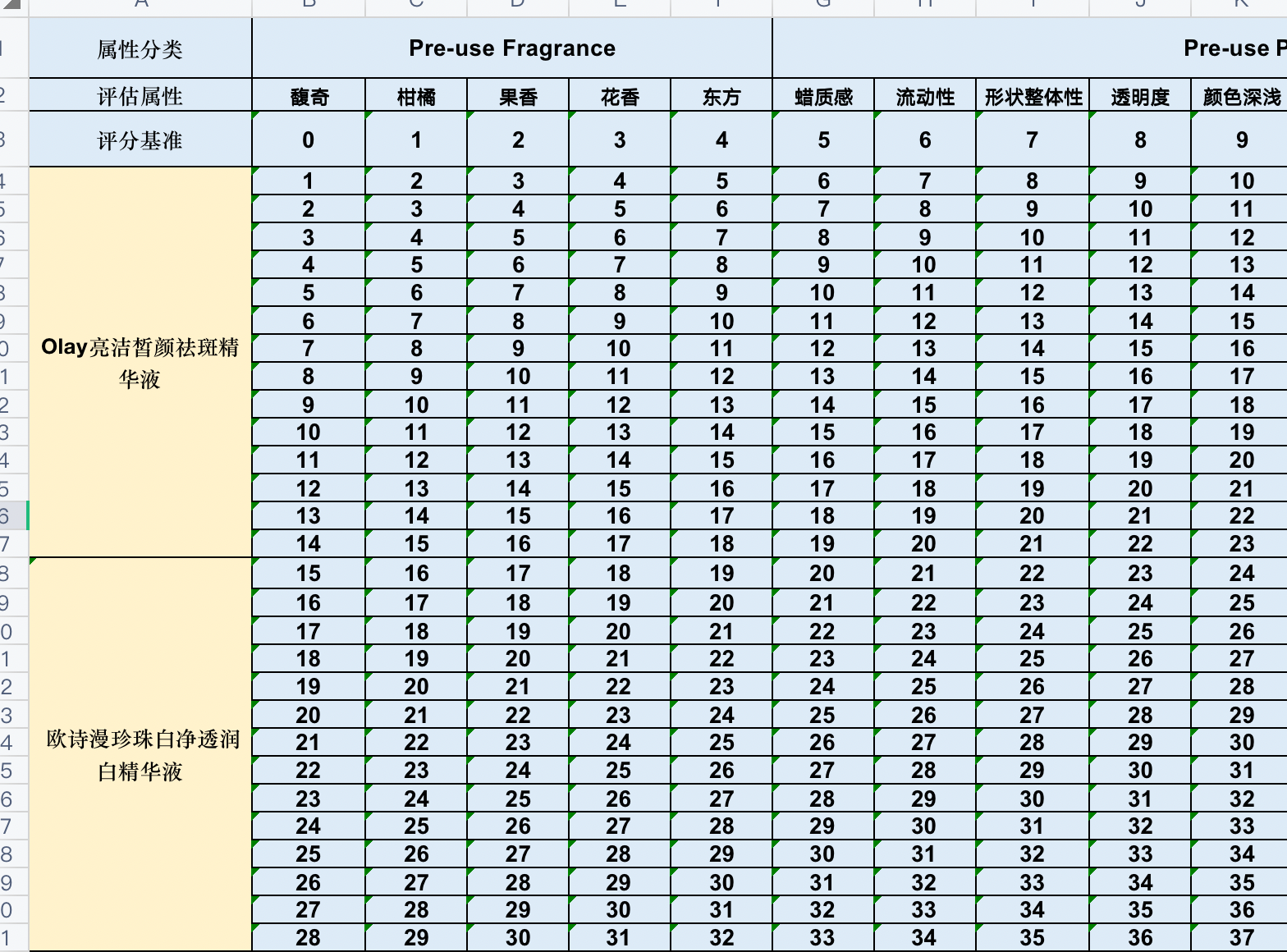
填充代码,可以给定超参数,填充表头,按行和按列填充
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import pandas as pd
def fill_pdna(df, row=[], col=[]):
"""
当excel的表头的行或列有合并单元格的情况时,只有第一个单元格是正确的,值,这时候需要使用前向填充ffill,即使用上一个单元格的内容填充当前为nan的单元格
但是填充的时候一般进行限制,只填充表头的前几行,或前几列
:param df:
:type df:
:param row: [] 表示所有行都使用前面的值进行填充,1表示第一行, eg: [1,2] 表示第1,2行用前面的值填充,-1表示不填充
:param col: []表示,所有列都使用前面的值填充, 0表示第一列, 注意行和列的其实索引位置不一样, -1表示不填充
:return:
:rtype:
"""
if not row:
df = df.ffill(axis=1)
if not col:
df = df.ffill(axis=0)
if col and col != [-1]:
for col_num in col:
df[col_num] = df[col_num].ffill(axis=0)
if row and row != [-1]:
for row_num in row:
df[:row_num] = df[:row_num].ffill(axis=1)
return df
def read_excel(excel_file):
"""
读取excel内容
:param excel_file:
:type excel_file:
:return:
:rtype:
"""
print(f"开始读取{excel_file}")
df = pd.read_excel(excel_file, header=None)
newdf = fill_pdna(df, row=[1,2,3], col=[0])
print(newdf)
|