多模态项目记录
项目目的,根据给定的图片和标题,判断所属的商品是库中的哪个商品
数据标注
开发一个前后端,前端标注人员可以根据提供的关键字进行搜索,搜索通过后端调取爬虫平台,实时获取爬取结果,因为爬取不稳定,添加额外缓存系统,当爬取过一次后,可以直接读取缓存,用户也可以不读取缓存,用户标注的结果提交到后台的mongo中保存
标注工具示例:
优化:
0. 提交按钮是浮动状态,方便用户下拉选中后也可以提交
1. 图标加上tmall官方链接,方便标注人员点击查看
2. 标注人员提交标注结果后,给与成功提示,否则给与失败提示,然后清空搜索框
3.Flask接口失败时,也会给与友好提示
4. 当用户搜索关键字为空时,默认给一个搜搜关键字示例
5. 给列表中每个搜索结果的a标签图片都加上点击事件,当是非checked状态时,点击后,变成checked状态,当是checked状态时,点击后变成非checked状态
6. 如果给的关键字在天猫中没有搜索到,返回也是空的,那么给出友好提示
7.判断用户提交的关联商品的名称是否为空,如果为空,提示一下
8. 追加原始的天猫的店铺的url链接,方便标注后一同导入到数据库中
9. 翻页后标签图片的点击事件失效问题修复
10. 增加强制爬取按钮:爬虫搜索(表示不使用缓存直接爬取)
1. 因为缓存的结果可能不存在,那么直接使用强制爬取
html中增加一个div,里面有一个button按钮
css中对这个div浮动,对button更改大小
js中添加事件,点击这个button后,传入的url多加一个spider=ture的参数
js通过DOM的location.search解析url参数,获取spider关键字状态,发送请求时根据spdier状态判断请求的force_update参数
使用模型
- 使用的Vilt模型,对比了单流架构和双流架构,单流架构更符合本项目,因为单流架构是汇总了一个文本和图片的高阶特征,而不是2个特征
- 首先使用模型继续预训练,我们下载了约70G数据,然后按照Vilt论文中所述,继续预训练,使其适应我们自己的数据集。
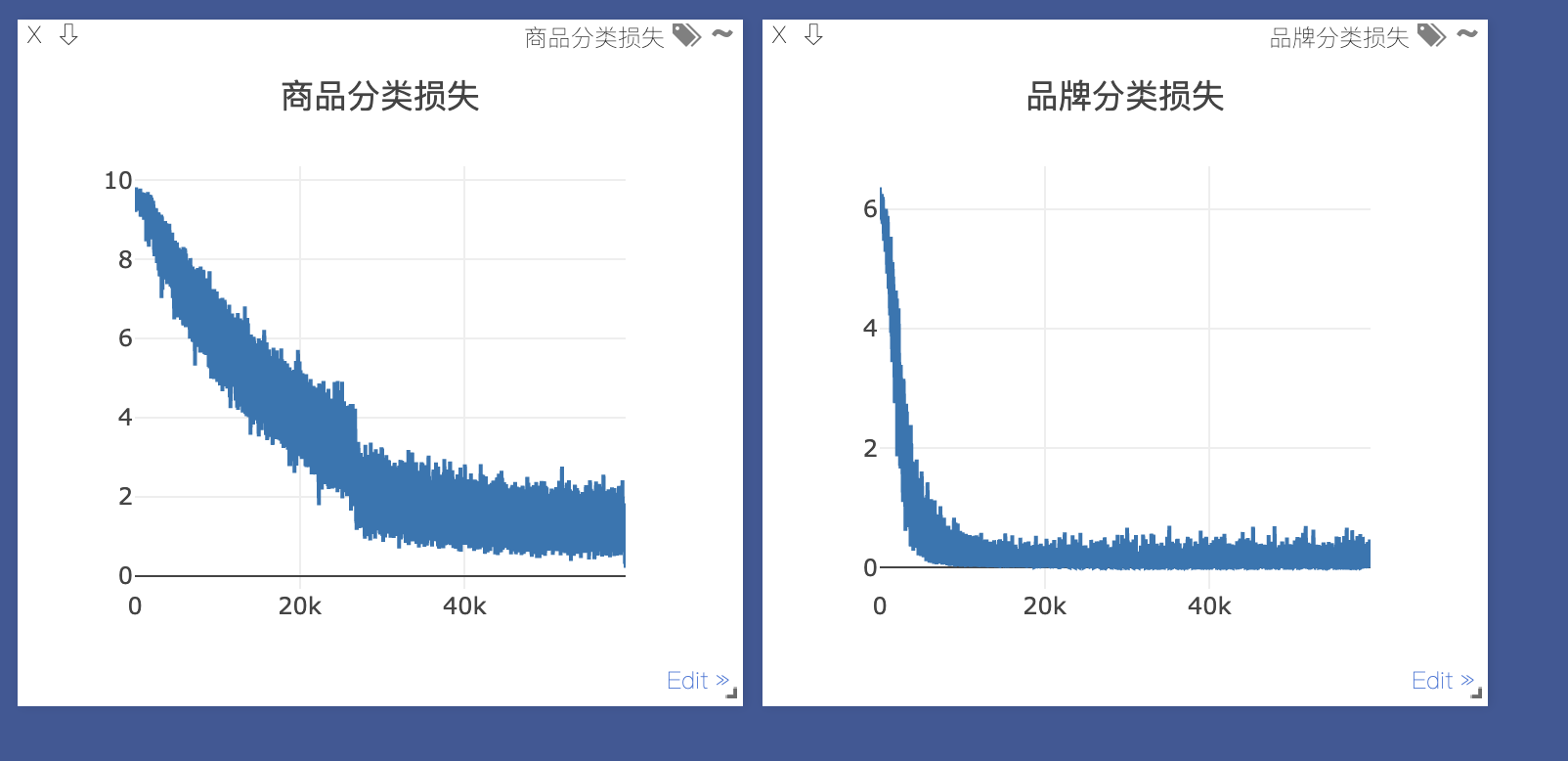
- 微调模型训练,自定义2个损失,品牌分类损失+商品分类损失,如果只是商品分类损失,模型没有学到品牌的信息点,很容易在品牌上就预测错了,那么商品上更预测错误了,结果能够比单纯的预测商品分类损失准确率提高10%左右
- 损失的权重,商品分类损失权重更大一些,因为品牌分类损失更简单,模型很容易就拟合了,结果证明商品分类损失权重大一些的话,准确率提高2%左右。
- 损失和训练step的对比图, 使用Visdom绘图, 明显损失相同的情况下,更难的任务拟合更慢
图0:预训练模型的MLM和ITM损失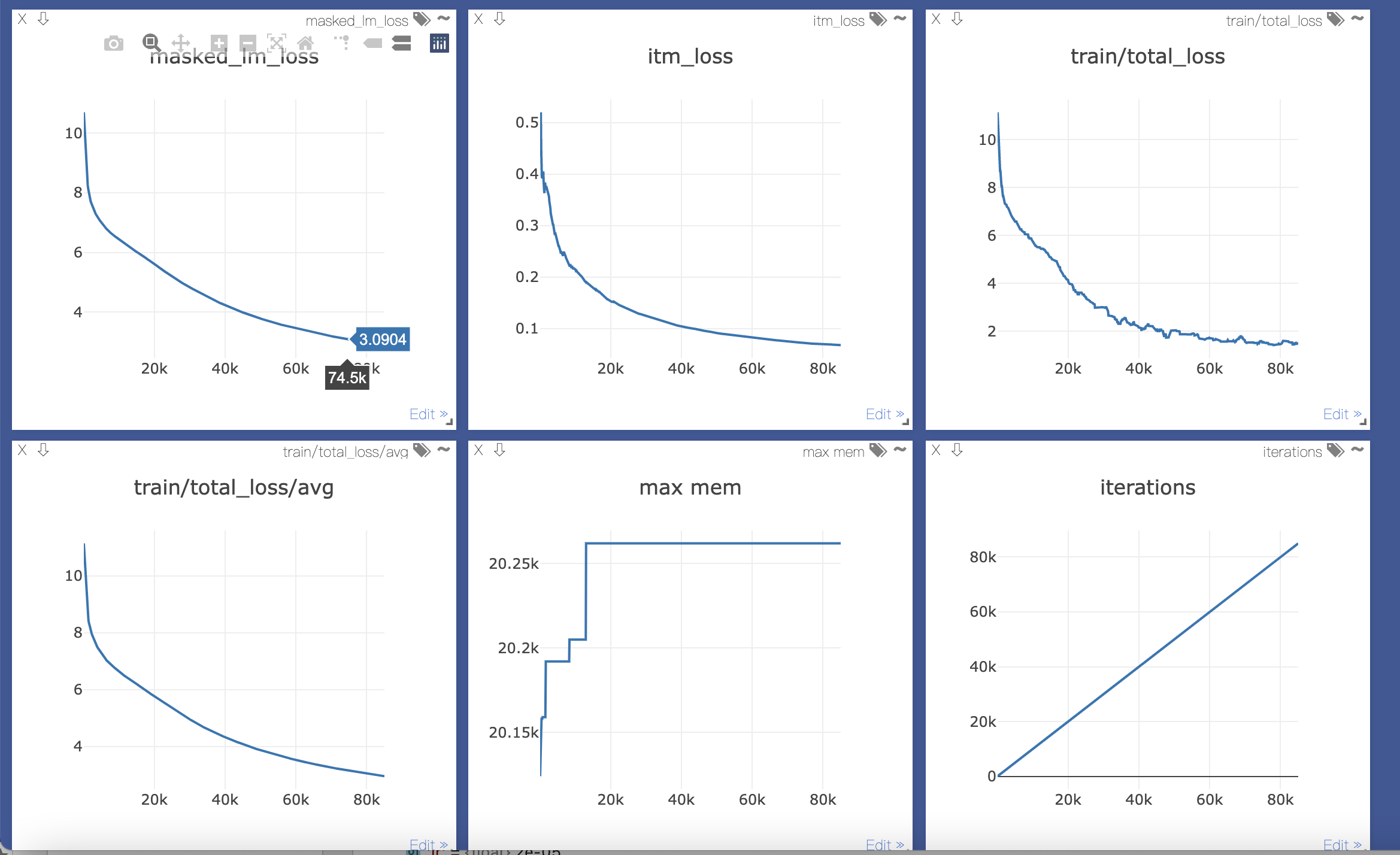
图1:损失权重相同的情况
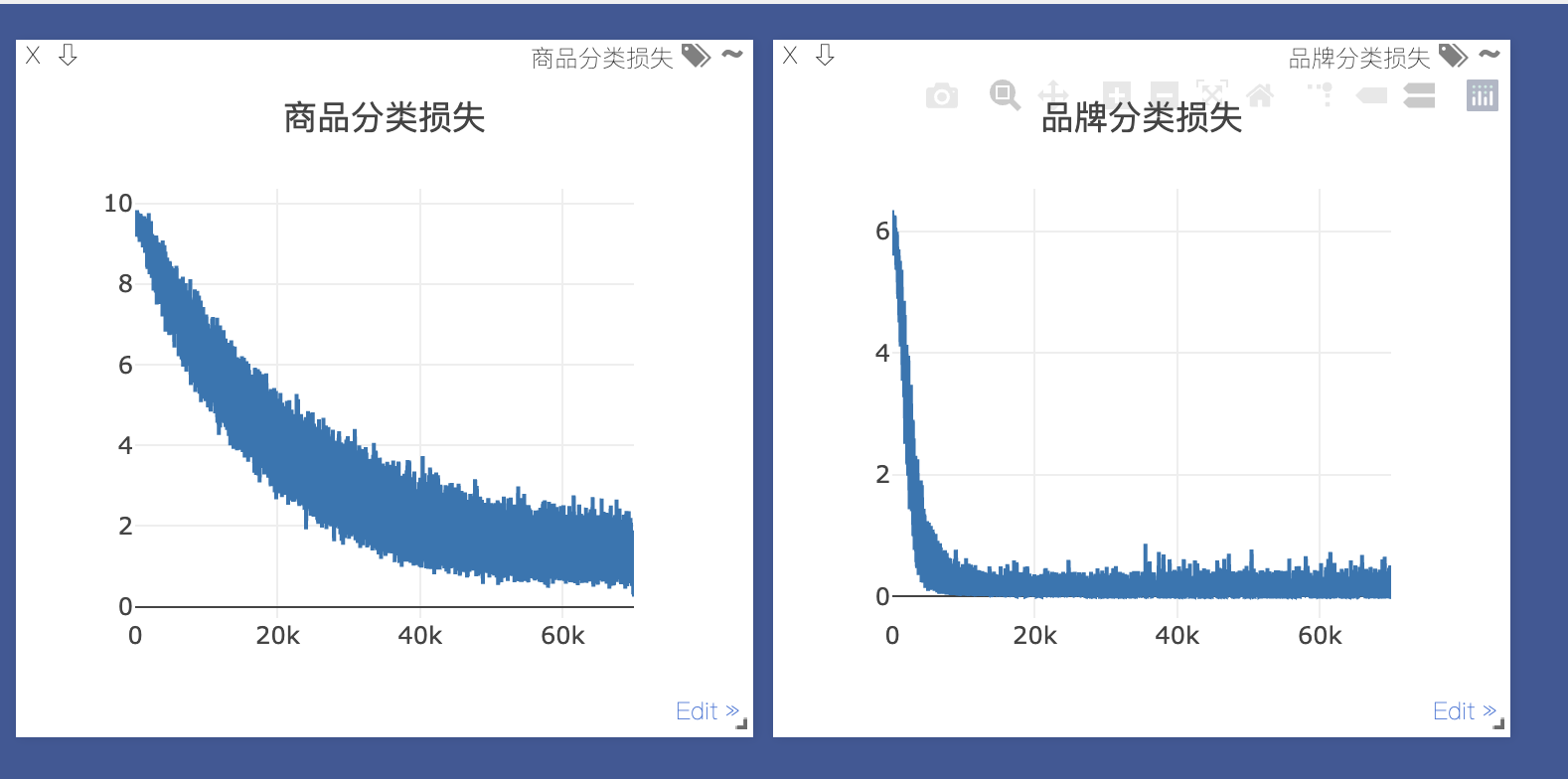
图2:损失权重不同的情况
Vilt总结:
ViLT:没有卷积或区域监督的视觉和语言transformer
定义
视觉和语言预训练(VLP),Vision-and-Language Pre-training
Vision-and-Language Transformer (ViLT)
以一种统一的方式处理两种模态
与以前的VLP模型的主要区别在于它对像素级输入的浅层无卷积嵌入。去除仅用于视觉输入的深层嵌入,通过设计大大减少了模型的大小和运行时间
图2d类型,原始像素的嵌入层很浅,计算量也很小,与文本token一样,将大部分的计算集中在模态交互的建模上
VSE:visual semantic embedding,视觉语义嵌入
MI:modality interaction 模态交互
单流方法: Single-Stream
各层操作图像和文本输入的拼接,例如UNITER
双流方法: Dual-stream
两种模态在输入层面没有拼接起来,类似ViLBERT,LXMERT
TE: textual embedder 文本嵌入器
VE: visual embedder 视觉嵌入器
使用碎片投影减小开销,使用一个32×32的补丁投影,只需要2.4M的参数
传统的区域特征需要步骤(参数量大):
一个区域建议网络(RPN)根据从CNN主干网汇集的网格特征提出感兴趣的区域(RoI)
非最大限度的抑制(NMS)将RoI的数量减少到几千个
RoI经过RoI头,成为区域特征
NMS再次应用于每个类别,最终将特征的数量减少到一百个以下
MSA: multiheaded self-attention 多头自注意力
ITM: Image Text Match: 图像文本匹配
ViT-B/32:代表Patch大小为32,即图片的每个碎片的大小,即32*32像素的,使用Conv2d即可
模型(图3)
模型结构
文本嵌入:词嵌入+位置嵌入+模态类型嵌入
视觉嵌入:图片切成块,线性投影嵌入+位置嵌入+模态类型嵌入
被串联成一个组合序列z0
transformer层
由多个块组成,每个块包含一个多头self-attention(MSA)和一个多层感知器(MLP)
层归一化(LN)在MSA和MLP之前
输出上下文序列zD
预训练目标
图像文本匹配(ITM)
以0.5的概率随机地用不同的图像来替换对齐的图像。一个单一的线性层ITM头将汇集的输出特征p投射到二分类的logits上,我们计算出负logits可能性损失作为我们的ITM损失
word patch alignment 词块对齐(WPA)损失
计算文本子集和视觉子集两个子集之间的对齐分数,使用非精确近似点法进行最优转译optimal transports(IPOT),并将近似的Wasserstein距离乘以0.1加到ITM损失中
可视化对齐结果见图4,图像部分和词进行了对齐
mask语言模型(MLM)
0.15的概率随机mask,预测被masked的文本ground truth标签
全词mask,而不是仅仅是词片wordpiecemask
使用RandAugment进行图像增强
数据集
预训练
微软COCO(MSCOCO),视觉基因组(VG),SBU字幕(SBU),以及谷歌概念字幕(GCC)
微调测试任务:
分类任务:VQAv2,NLVR2
检索任务: MSCOCO, Flickr30K
开发多模态模型评估系统
- 开发2个Tab标签,一个是测试预测,一个是统计
- 测试预测逻辑
用户提交关键词
调用/api/goodslist获取爬取结果
对爬取结果的图片进行本地缓存
对结果处理后提交多模态模型预测品牌和所属商品
对预测结果进行展示
展示预测结果
展示图片,title,价格,店铺
用户判断预测结果是否正确
如果错误,给出正确的预测商品
提交用户判断结果到后台
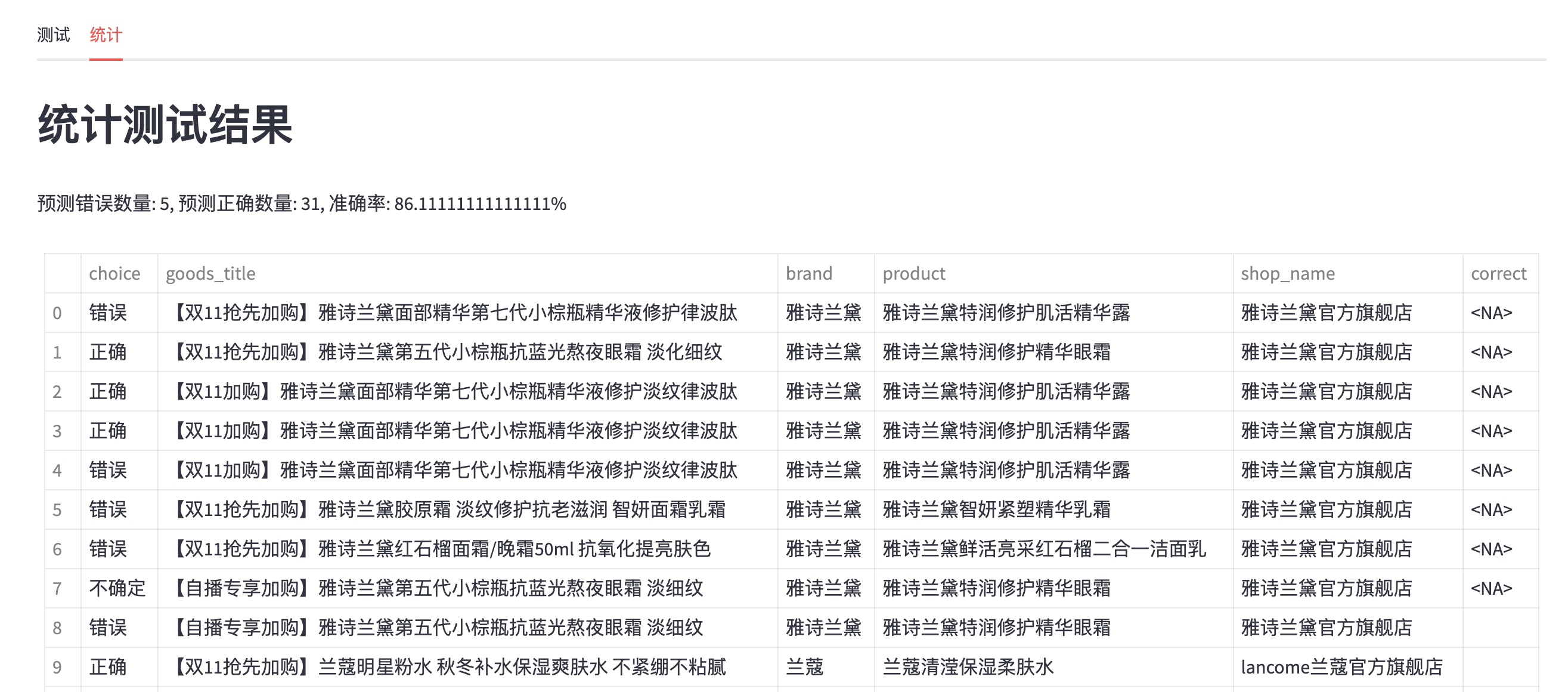
统计逻辑
从mongo中读取用户人工判断的结果
展示所有数据的表格形式
统计模型判断正确和错误的结果,显示准确率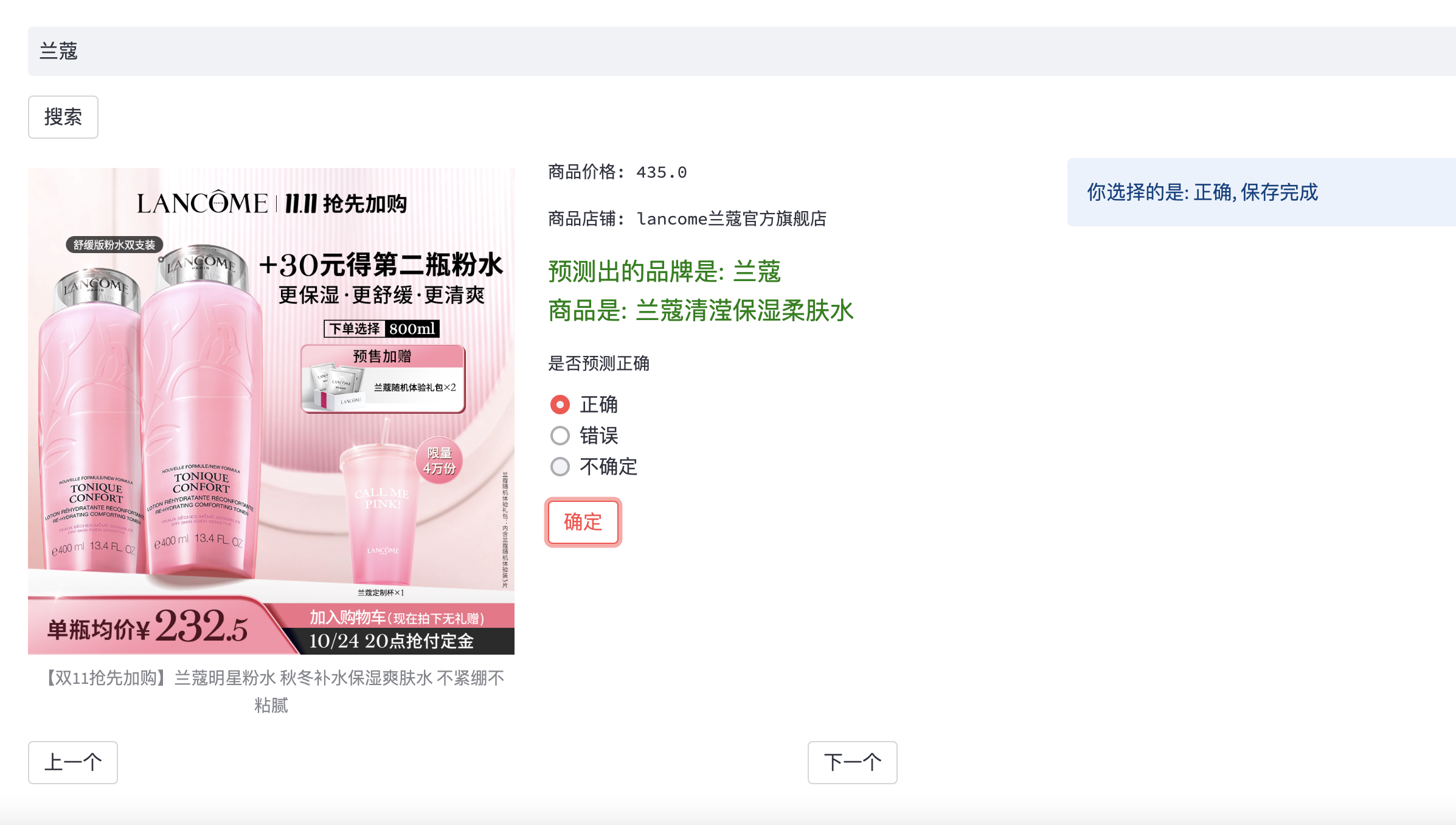
- 测试预测逻辑