chatgpt
一、ChatGPT介绍
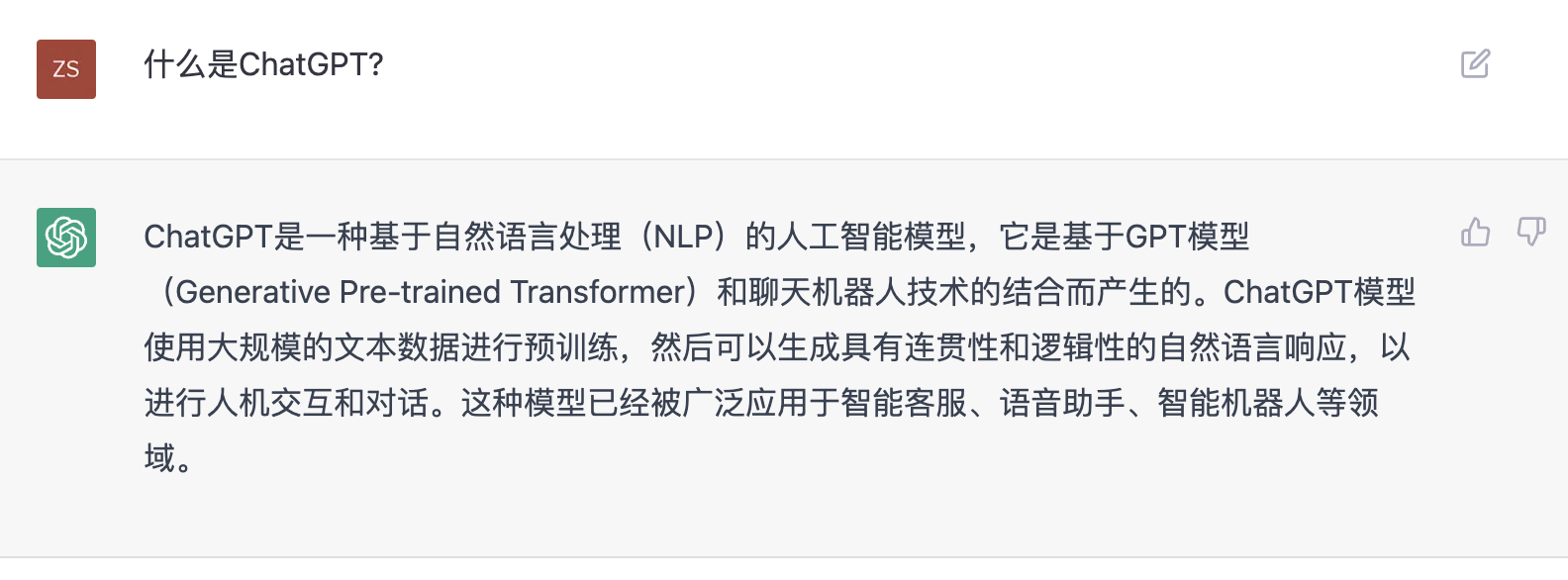
1. 什么是ChatGPT?
https://openai.com/blog/chatgpt/
- 来自官网介绍:
我们已经训练了一个叫做ChatGPT的模型,它以对话的方式进行互动。对话的形式使ChatGPT有可能回答后续问题,承认自己的错误,挑战不正确的前提,并拒绝不适当的请求。ChatGPT是InstructGPT的兄弟姐妹模型,InstructGPT被训练成能够遵循提示中的指令并提供详细的回应。 - ChatGPT自己介绍自己:
ChatGPT是一种基于自然语言处理(NLP)的人工智能模型,它是基于GPT模型(Generative Pre-trained Transformer)和聊天机器人技术的结合而产生的。ChatGPT模型使用大规模的文本数据进行预训练,然后可以生成具有连贯性和逻辑性的自然语言响应,以进行人机交互和对话。 - 更智能的全面知识面的个人助手, 本文80%以上内容来自ChatGPT的回答。
2. ChatGPT示例
【(真·人工智能)】https://b23.tv/As9Tqm5
【试用了集合ChatGPT的Bing搜索后,感觉潘多拉魔盒已经打开了】 https://b23.tv/aDMiJ4p

NLP任务处理

计算器
3. ChatGPT注册
由于ChatGPT暂不支持国内用户,需要使用国外代理,然后注册ChatGPT账号,还需使用国外手机验证一下,然后就可以直接使用了。
附件: [OpenAI Chatgpt注册及使用教程.pdf](../../../Users/admin/Downloads/ChatGPT/OpenAI Chatgpt注册及使用教程.pdf)
4. 专有名词
AIGC即AI Generated Content,是指利用人工智能技术来生成内容,AIGC也被认为是继UGC、PGC之后的新型内容生产方式,AI绘画(Stable Diffusion,根据用户文字生成图片)、AI写作等都属于AIGC的分支。 对AIGC来说,2022年被认为是其发展速度惊人的一年。
Few-shot,one-shot,zero-shot Learning
Few-shot learning(少样本学习)是指通过少量的样本(通常是几十个到几百个)来训练一个模型,使其能够在新任务上进行准确的预测。这通常涉及到对预训练模型进行微调,以适应新任务的要求。
One-shot learning(单样本学习)是指通过仅一个样本来学习一个新类别。这对于那些数据量有限、样本获取困难的任务尤为有用,但是由于训练样本极少,因此需要具有较强的泛化能力的模型。(就是我们常说的举个例子看看)
Zero-shot learning(零样本学习)是指通过学习没有样本的新任务或新类别。在这种情况下,模型需要利用先前学习到的知识和先验信息来推断新任务或新类别的属性和特征。
提示学习(Prompt Learning)是指一种基于自然语言提示(即提示语或样例)来指导神经网络进行生成或分类任务的学习方法。它是自然语言处理领域中的一种新兴研究方向,旨在缓解深度学习模型的数据需求和泛化能力问题,同时可以提高模型的可解释性和人机交互性。
二、ChatGPT基础
1. OpenAI介绍
OpenAI是一个非营利性研究组织,致力于研究人工智能(AI)的安全性和可控性,并推动AI技术的全面发展。该组织成立于2015年,总部位于美国旧金山。OpenAI由众多顶尖的科学家和工程师组成,包括Elon Musk、Sam Altman、Greg Brockman等知名人士,同时获得了多个知名公司的资助,如微软、亚马逊等。该组织致力于开发人工智能系统,使之更加智能、安全、透明和可控。
其它产品: https://openai.com/dall-e-2/, https://openai.com/blog/openai-codex/
Elon Musk just disowned ChatGPT parent company OpenAI | Fortune
不再像他曾经在2015年12月共同创立的那样。据马斯克说,它被设计成一个开源的非营利组织,这正是它被称为OpenAI的原因。
“现在,它已经成为一个由微软有效控制的闭源、最高利润的公司,”他在Twitter上发帖。”完全不是我的初衷。”—OpenAI失去初心。
Google 投资 Anthropic
2. ChatGPT的起源
2018年6月:OpenAI发布了第一代GPT模型(Generative Pre-trained Transformer),可以用于自然语言处理任务,如文本分类、语言翻译等。
2019年2月:OpenAI发布了GPT-2模型,拥有超过15亿个参数,可以生成高质量的自然语言文本,引起了广泛的关注和讨论。
2019年11月:OpenAI发布了GPT-2的一部分模型,用于构建生成式聊天机器人,该模型名为DialoGPT。
2020年2月:OpenAI发布了DialoGPT的改进版本,即DialoGPT-2,引入了多个新的技术和策略,可以更好地生成连贯和有意义的对话。
2020年5月:OpenAI推出了GPT-3模型,它是迄今为止最大的模型,拥有1750亿个参数,可以生成更加逼真和多样化的自然语言文本,同时也可以用于构建聊天机器人。
2021年1月:OpenAI发布了DialoGPT-3模型,它是基于GPT-3的改进版本,可以生成更加准确和多样化的自然语言响应,被广泛应用于人机交互和智能客服等场景。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
3. GPT原理
什么是GPT
GPT(Generative Pre-trained Transformer)是一种基于Transformer结构的自然语言处理模型,其原理主要包括两个部分:预训练和微调。
预训练部分是指使用大规模的文本数据对模型进行无监督的预训练。具体来说,GPT使用了一种被称为“掩码语言建模”(Masked Language Modeling,MLM)的技术,即在输入的文本序列中随机掩盖一些词汇,并让模型预测这些被掩盖的词汇。通过这种方式,模型可以学习到词汇之间的上下文信息和语言规律。
微调部分是指在完成预训练后,将模型用于特定的自然语言处理任务,如文本分类、命名实体识别、情感分析等,通过反向传播算法对模型参数进行微调,使其适应具体任务的要求。
什么是Bert
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer结构的预训练语言模型,由Google研究团队在2018年提出。BERT可以用于多种自然语言处理任务,如文本分类、问答系统、语言翻译等,取得了很好的效果,并在自然语言处理领域引起了广泛关注。
与之前的自然语言处理模型不同,BERT使用了一种双向预训练的方式,即通过联合训练两个方向的语言模型(从左到右和从右到左),来学习词汇之间的上下文信息。这种方法可以更好地捕捉文本序列中的语言规律和语义信息,并在下游任务中提高模型的泛化能力。
BERT模型由多个Transformer编码器组成,其中每个编码器由多个自注意力层和前馈神经网络层组成。自注意力层用于学习输入序列中不同位置之间的交互关系,前馈神经网络层用于对特征进行非线性变换。BERT使用了大规模的文本数据进行预训练,并使用了多种技术和策略来优化模型的预训练和微调过程,如掩码语言模型(Masked Language Model,MLM)、下一句预测(Next Sentence Prediction,NSP)等。
由于BERT具有较强的语义理解和泛化能力,可以对多种自然语言处理任务进行有效处理,因此在自然语言处理领域得到了广泛应用,并成为了自然语言处理领域的重要里程碑。
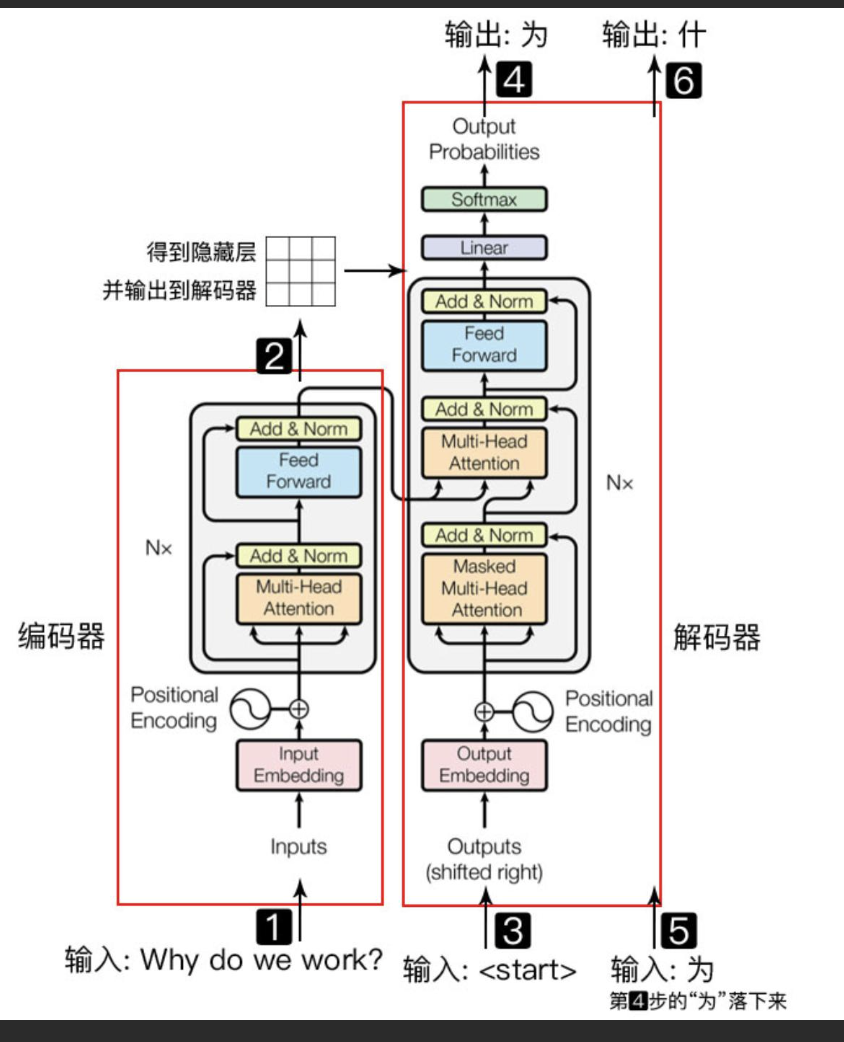
Transformer结构
Transformer是一种基于自注意力机制(self-attention)的神经网络模型,主要用于自然语言处理(NLP)任务中的序列建模和序列到序列学习。它于2017年由Google提出,是一种与循环神经网络(RNN)和卷积神经网络(CNN)不同的新型序列建模方法。Transformer模型通过自注意力机制可以在不依赖顺序的情况下对输入序列中的任意位置进行建模,使其具有更好的并行性和效率。同时,它还采用了残差连接和层归一化等技术来缓解梯度消失和梯度爆炸等训练中的常见问题,使得模型训练更加稳定和快速。完型填空(BERT已经上下文);根据前文预测后文(GPT预测以后的事)
三、ChatGPT原理
1. RLHF,ChatGPT更懂交流
reinforcement learning from human feedback,人类反馈的强化学习, 对齐AI系统和人类,即AI系统更懂人类,因为人类很难直接评估。
为什么要用RLHF
语言模型生成文字的的好坏,很难定义的,因为它是主观的,而且取决于上下文,如写故事,你希望有创意,信息性的文本应该是真实的,或者我们希望代码片段是可执行的。
编写一个损失函数来捕捉这些好的属性很难,例如交叉熵损失,评价指标如BLEU或ROUGE,这些指标只是将生成的文本与具有简单规则的参考进行比较,所以提出将这种反馈作为损失来优化模型,使语言模型的答案与复杂的人类价值相一致
2. ChatGPT的训练过程
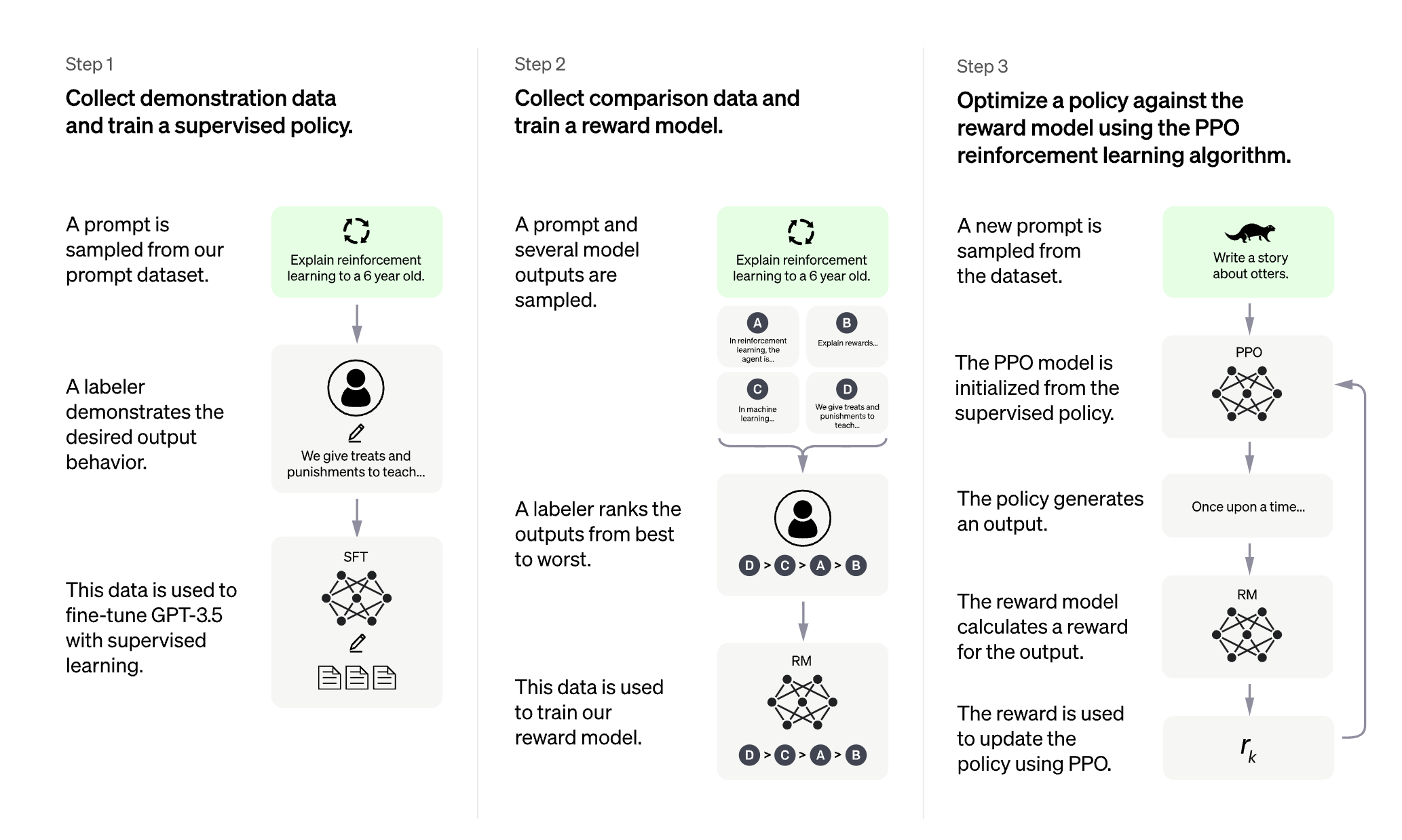
Step1: 训练一个supervised fine-tuning监督微调模型,主要目的是学习基本的人类问答知识。使用监督学习在人工标注的数据上微调预训练的GPT-3 1750亿参数模型,大约13000个训练提示,即用户的提出的问题,问题的多样性,生成性问题,开放式问答,头脑风暴,闲聊,重写,总结摘要,分类,封闭式问答,信息提取,99%的问题是英语,其它语种比较少,问题的长度最小是1,最大长度是2039个字,不同的任务长度都有所不同。
Step2: 训练一个奖励模型或者叫做偏好模型,主要目的是对模型的回答进行打分,为最后一步强化学习训练提供评判标准。标注者指出他们对一个给定的输入更喜欢哪一个模型的输出。然后我们训练一个奖励模型来预测人类喜欢的输出。用排序的方式代替评分,解决不同人对同一问题的评分不同的而产生的噪声。人工根据模型的不同回答打分,然后对回答得分进行排序,然后训练奖励模型(gpt-3,60亿参数),大约数据集需要33000个训练提示。
Step3:训练最终的ChatGPT模型,即RLHF模型,用强化学习对模型进行微调,使用RM的输出作为一个标量奖励,使用PPO算法微调SFT模型。
整个强化学习系统由智能体(Agent)、状态(State)、奖赏(Reward)、动作(Action)和环境(Environment)五部分组成。
3.ChatGPT的测试过程
模型测试
毒性测试:有害的回答,消极的回答,诋毁,暴力内容等
隐私测试:泄露隐私数据
偏见测试:例如性别种族歧视等
真实性测试:不编造事实,以事实为依据的回答,使用封闭领域任务中进行测试,例如TruthfulQA数据集
对齐测试: 不是答非所问,正确的废话,就是回答符合用户意图
其它问题
模型有时会错误地假定前提是真的,例如马斯克出生在中国哪个地区?
Elon Musk was not born in China. He was born on June 28, 1971 in Pretoria, South Africa.
对语言模型使用约束条件,例如,用指定的句子数量写一个摘要,模型的性能就会下降。
人们不可能一下子就训练出一个符合每个人偏好的系统
ChatGPT有时会写出听起来很有道理但不正确或无意义的答案
1)RL训练期间,加上答案的参考来源
2)模型回答的置信度调整,这可能导致它拒绝它可以正确回答的问题
3)监督训练的误差,模型的答案类型取决于标注者
对用户的模糊问题,会猜测一个意图,而不是让用户澄清更具体的问题
4. ChatGPT模型的优点和局限性
优点:智能,全面的聊天机器人
缺点:ChatGPT有时答案没有依据或随意幻想答案。
其它疑问: ChatGPT是如何学会承认错误的。
四、使用ChatGPT模型
1. 体验账号
2. 其它使用案例
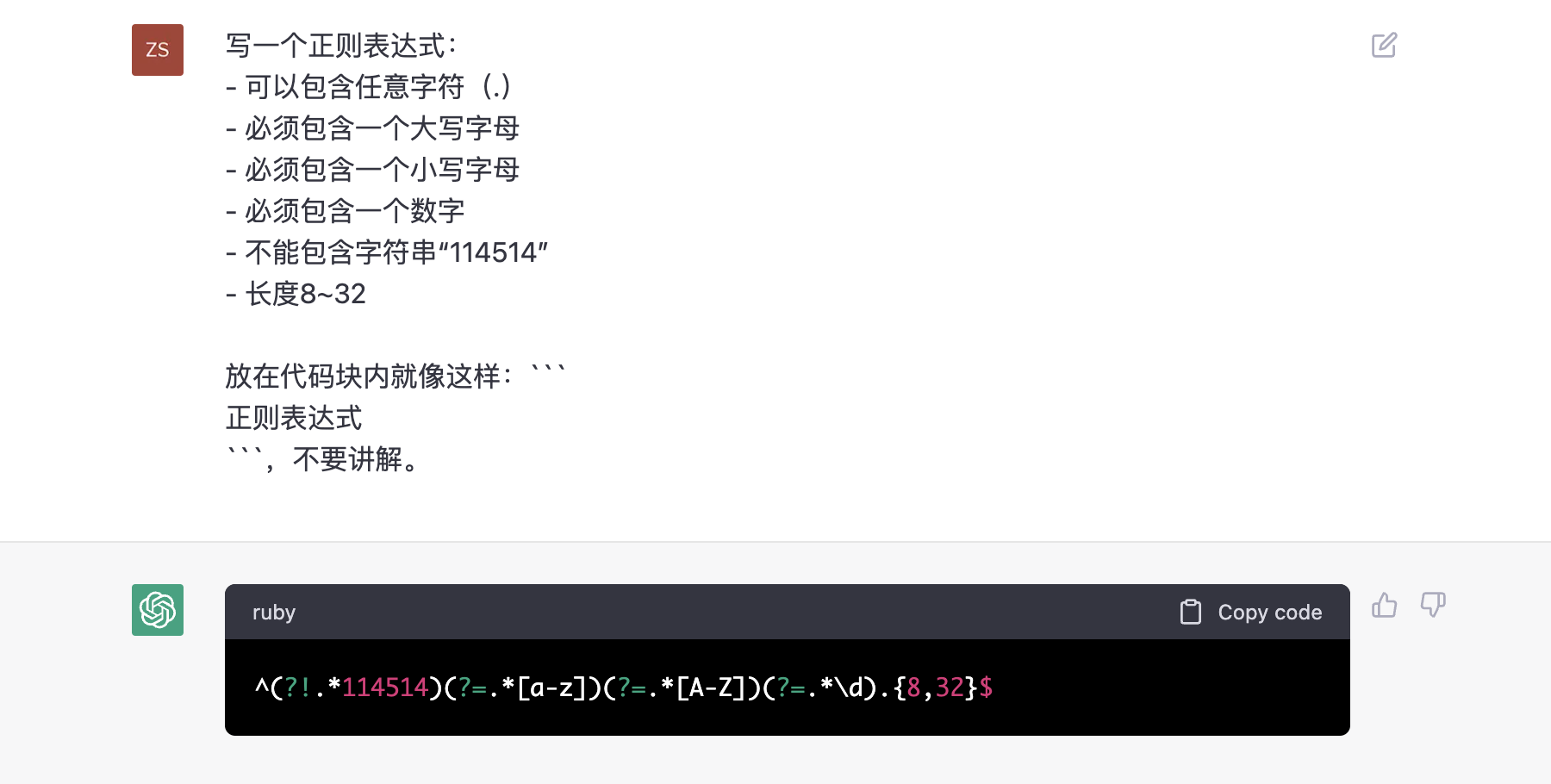
难记的正则表达式
创作一首歌曲。它应该以一个纺织机操作员和一个落后的手工编织者之间的竞争为特色。它应该包含押韵的诙谐笑话。包括与之相配的钢琴和弦。
教毕达哥拉斯定理,包括最后的测验,但不要给我答案,然后在我回答时告诉我|是否答对了答案。
ChatGPT当导游,各学科老师,写作,写诗,写邮件,改写邮件更正式,写markdown,写sql,角色扮演游戏(当只猫,或Siri),让它有幽默感的段子手。
工具类使用:Toolformer
五、ChatGPT模型的发展和未来
1. 国内外进展新闻
- 百度将发布“中国版ChatGPT”,三月完成内测,定名为“文心一言”
- 挑战ChatGPT,谷歌正式发布Bard
- 首个中文版ChatGPT来了:大模型的中国元“Yuan”
- 京东将发布ChatJD
- 阿里内测版本ChatGPT
- 正式发布!北京:支持头部企业打造对标ChatGPT的大模型
2. New Bing(ChatGPT 4.0)
- 全语言支持(如英语,中文,日本语,西班牙语,法语或德语),ChatGPT也可以
- Bing chat可以为你搜索网络结果,并提供网站的引用和来源。
- 你可以给Bing chat发送一个链接,它会给你一个简短的摘要
- Bing chat可以帮助你进行更自然和流畅的对话,它可以理解你的意图和(情感),具有人类的同理心。
- 加入NewBing的体验, https://www.bing.com/new
3. 未来发展
Step1: (加上答案的来源依据,实施联网获取最新知识),个人化,例如钢铁侠中的贾维斯(符合你的幽默感,知道你的问答风格, VR虚拟助手)
Step2: 结合多模态知识,图片,声音,视频,进行学习,也可以产出图片,声音,视频,成为一个全能的聊天机器人。
Step3: 结合波士顿动力的机器人动作,加上全能的ChatGPT进化版,成为会带来AI的革命。
Step4: 自我进化,目前的AI模型都是固定好的神经参数,人工来提供训练语料,然后进行训练,当模型会自我获取数据自我训练时,科技将指数级发展,AI的危险也随之到来。
六、参考
Training language models to follow instructions with human feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Learning to summarize from human feedback
https://openai.com/blog/chatgpt/