1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
|
import time
import random
import json
import requests
import pandas as pd
import collections
import numpy as np
import matplotlib.pyplot as plt
sentiment_mapper = {
"开心": "Happy",
"满意": "Happy",
"喜欢": "Happy",
"愉快": "Pleased",
"信任": "Trusting",
"怀念": "Trusting",
"值得": "Valued",
"赞叹": "Valued",
"支持": "Valued",
"关心": "Cared for",
"安全": "Safe",
"关注": "Focused",
"同情": "Focused",
"激动": "Stimulated",
"刺激": "Stimulated",
"能量": "Energized",
"纵容": "Indulged",
"感兴趣": "Interested",
"探索": "Exploratory",
"不满意": "Unsatisfied",
"不信任": "Unsatisfied",
"纠结": "Frustrated",
"困惑": "Frustrated",
"失望": "Disappointed",
"激怒": "Irritated",
"压力": "Stressed",
"不开心": "Unhappy",
"无聊": "Unhappy",
"无趣": "Unhappy",
"忽视": "Neglected",
"焦虑": "Hurried",
"焦急": "Hurried",
}
sentimeng_group = {
"Adovcacy": ["Happy","Pleased"],
"Recommendation": ["Trusting","Valued","Cared for", "Safe", "Focused"],
"Attention": ["Stimulated","Energized","Indulged","Interested","Exploratory"],
"Destroyer": ["Unsatisfied","Frustrated","Disappointed","Irritated","Stressed","Unhappy","Neglected","Hurried"],
}
sentiment_color = {
"Happy": "blue",
"Pleased": "skyblue",
"Trusting": "green",
"Valued": "lightgreen",
"Cared for": "darkgreen",
"Safe": "yellow",
"Focused": "gold",
"Stimulated": "orange",
"Energized": "red",
"Indulged": "darkred",
"Interested": "purple",
"Exploratory": "cyan",
"Unsatisfied": "pink",
"Frustrated": "deeppink",
"Disappointed": "hotpink",
"Irritated": "lightpink",
"Stressed": "deeppink",
"Unhappy": "lightyellow",
"Neglected": "yellow",
"Hurried": "lightcyan",
}
def predict_chat(excel='/Users/admin/Downloads/20230506原始数据.xlsx'):
"""
预测excel中的数据
:return:
返回结果:
"""
save_excel = '/Users/admin/Downloads/20230506_处理结果.xlsx'
df = pd.read_excel(excel)
prompt = '分析下面的评论中的细微情感,并归类到以下的情感维度中的一个或几个,情感维度包括:开心,愉快,信任,值得,关心,安全,关注,刺激,能量,纵容,感兴趣,探索,不满意,纠结,失望,激怒,压力,不开心,忽视,焦虑, 并给出你认为的情感强度,量化量化上述情绪,值是1-5,答案用json格式返回,示例是:[{"信任": 1}, {"感兴趣": 4}, {"失望": 3}],并在答案末尾给出导致这种情感的原因?'
data = []
for idx, row in df.iterrows():
print(f"正在处理第{idx}条数据")
start_time = time.time()
text = row['text']
result = do_predict(prompt, text)
response = result[0]['result']['choices'][0]['message']
content = response["content"]
print(f"content返回结果: {content}")
data.append({
"text": text,
"response": content
})
end_time = time.time()
cost_time = end_time - start_time
df = pd.DataFrame(data)
df.to_excel(save_excel, index=False)
print(f"处理完成, 保存结果到: {save_excel}")
def do_predict(prompt, text):
"""
Args:
prompt ():
text ():
Returns:
"""
host = 'mysig'
host_sentiment = f'http://{host}:4636'
data = [{"prompt": prompt,"text": text}]
params = {'data': data}
headers = {'content-type': 'application/json'}
url = "{}/api/openai".format(host_sentiment)
r = requests.post(url, headers=headers, data=json.dumps(params), timeout=1200)
result = r.json()
if r.status_code == 200:
print(f"返回结果: {result}")
assert len(result) == len(data), f"返回结果个数不正确, 期望个数: {len(data)}, 实际个数: {len(result)}"
else:
print(r.status_code)
print(result)
return result
def mapper_excel():
db_excel = '/Users/admin/Downloads/20230506原始数据.xlsx'
src_excel = '/Users/admin/Downloads/20230506_处理结果.xlsx'
save_excel = '/Users/admin/Downloads/20230506_处理结果_映射.xlsx'
df = pd.read_excel(src_excel)
for idx, row in df.iterrows():
response = row['response']
print(f"正在处理第{idx}条数据,数据是: {response}")
response = response.replace('{\n ', '{').replace('\n}', '}').replace(',\n', ',').replace("'",'')
response_split = response.split('\n')
if len(response_split) == 1:
response_split = response.split('],')
response_split[0] = response_split[0] + ']'
if len(response_split) == 1:
response_split = response.split('] 原因')
response_split[0] = response_split[0] + ']'
first_part = response_split[0]
first_part = first_part.replace('。', '').strip(',')
json_data_list = json.loads(first_part)
new_json_data = {}
if isinstance(json_data_list, list):
for one_data in json_data_list:
for key, value in one_data.items():
english_key = sentiment_mapper[key]
new_json_data[english_key] = value
else:
for key, value in json_data_list.items():
english_key = sentiment_mapper[key]
new_json_data[english_key] = value
reason = '。'.join(response_split[1:])
df.loc[idx, 'response'] = json.dumps(new_json_data)
df.loc[idx, 'reason'] = reason
db_df = pd.read_excel(db_excel)
db_df = db_df[['channel', 'text']]
df = pd.merge(db_df, df, on='text', how='left')
df.to_excel(save_excel, index=False)
print(f"列现在是: {df.columns}")
print(f"处理完成, 保存结果到: {save_excel}")
def do_plot():
src_excel = '/Users/admin/Downloads/20230506_处理结果_映射.xlsx'
sentiment_mean_png = '/Users/admin/Downloads/20230506_处理结果_映射_情感维度平均值.png'
df = pd.read_excel(src_excel)
sentiments = df['response'].tolist()
sentiments = [json.loads(sentiment) for sentiment in sentiments]
sentiment_list = collections.defaultdict(list)
for sentiment in sentiments:
for key, value in sentiment.items():
sentiment_list[key].append(value)
print(f"125个数据中,情感维度的分布是: {len(sentiment_list)}")
sentiment_mean = {}
for key, value in sentiment_list.items():
sentiment_mean[key] = np.mean(value)
print(f"情感维度的平均值是: {sentiment_mean}")
x = list(sentiment_mean.keys())
y = list(sentiment_mean.values())
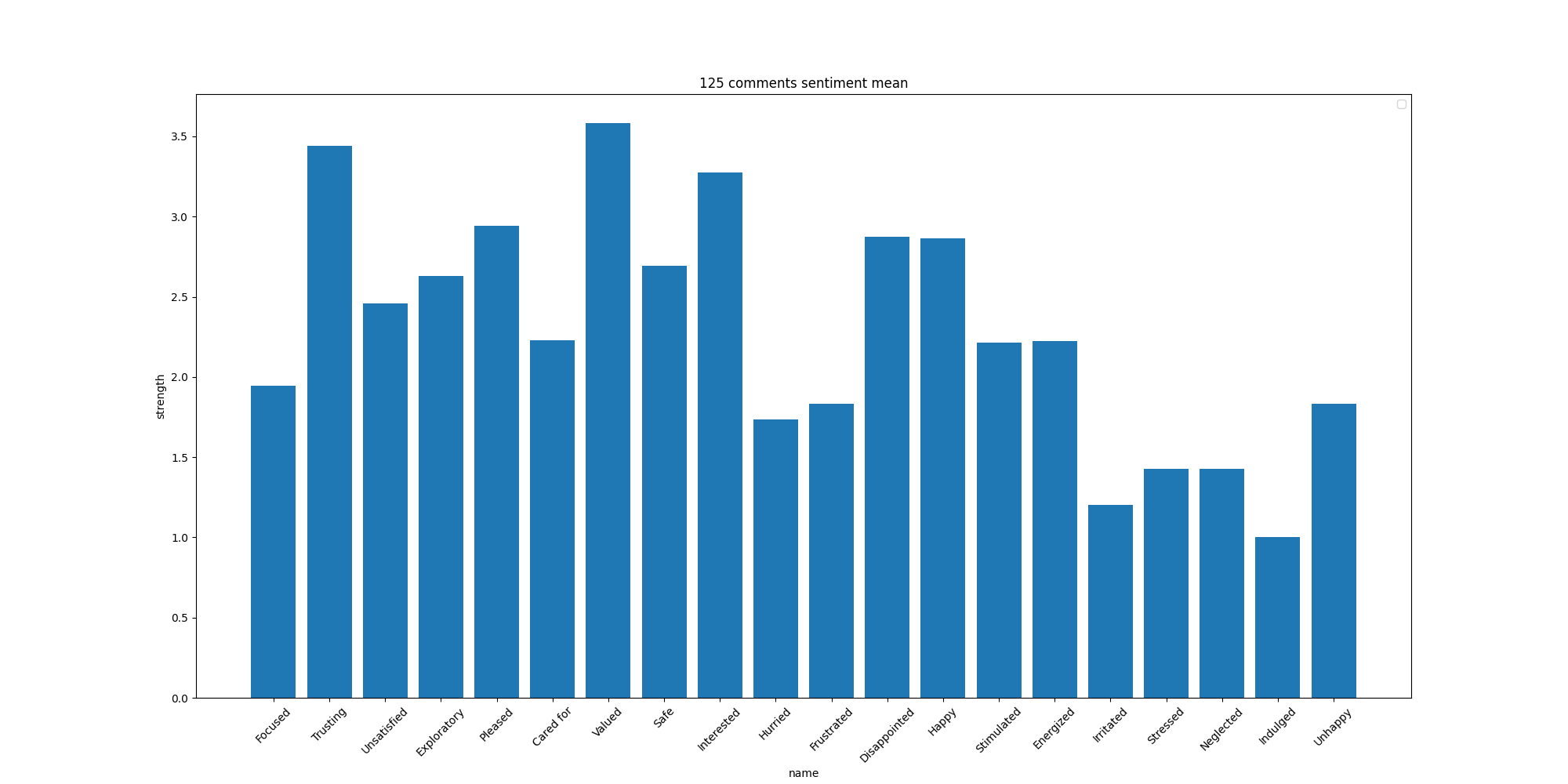
plt.figure(figsize=(20, 10), dpi=100)
plt.bar(x, y)
plt.xticks(rotation=45)
plt.xlabel("name")
plt.ylabel("strength")
plt.legend(loc="upper right")
plt.title(f"125 comments sentiment mean")
plt.savefig(sentiment_mean_png)
plt.clf()
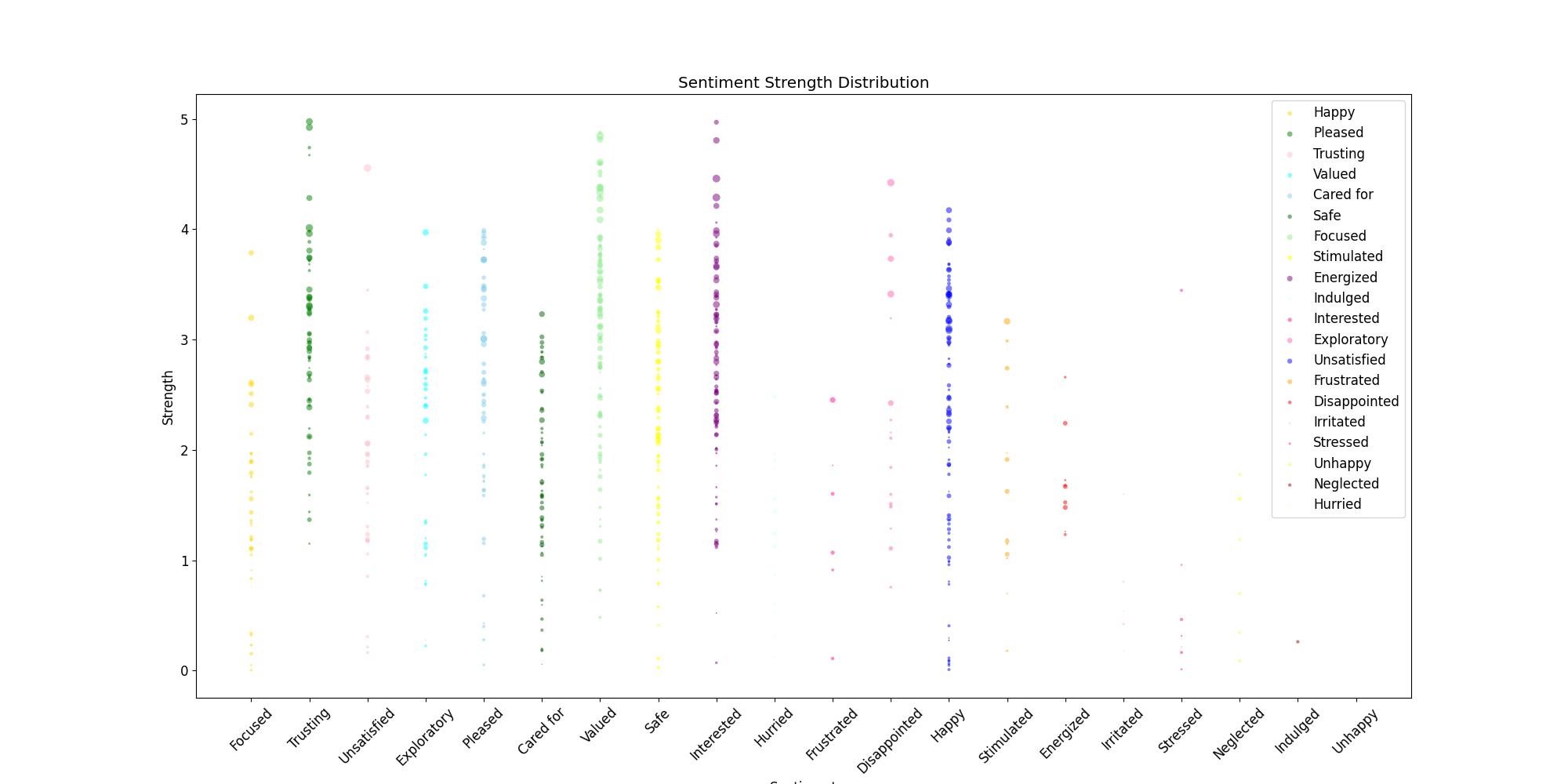
plt.figure(figsize=(20, 10), dpi=100)
plt.rcParams.update({'font.size': 12})
for i, (name, value) in enumerate(sentiment_list.items()):
color = sentiment_color[name]
size = [i*random.randint(1,10) for i in value]
value = [i-random.random() for i in value]
plt.scatter([i+1]*len(value), value, s=size, c=color, alpha=0.5, edgecolors='none')
plt.xticks(range(1, len(sentiment_list)+1), list(sentiment_list.keys()), rotation=45)
plt.legend(sentiment_color, loc="upper right")
plt.xlabel("Sentiment")
plt.ylabel("Strength")
plt.title(f"Sentiment Strength Distribution")
plt.savefig('/Users/admin/Downloads/20230506_处理结果_映射_情感维度分布图.png')
if __name__ == '__main__':
predict_chat()
mapper_excel()
do_plot()
|