1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| def plot_prompt_token_num2(df_data):
"""
根据prompt类型,统计总的问题长度,prompt长度
Args:
df_data ():
Returns:
"""
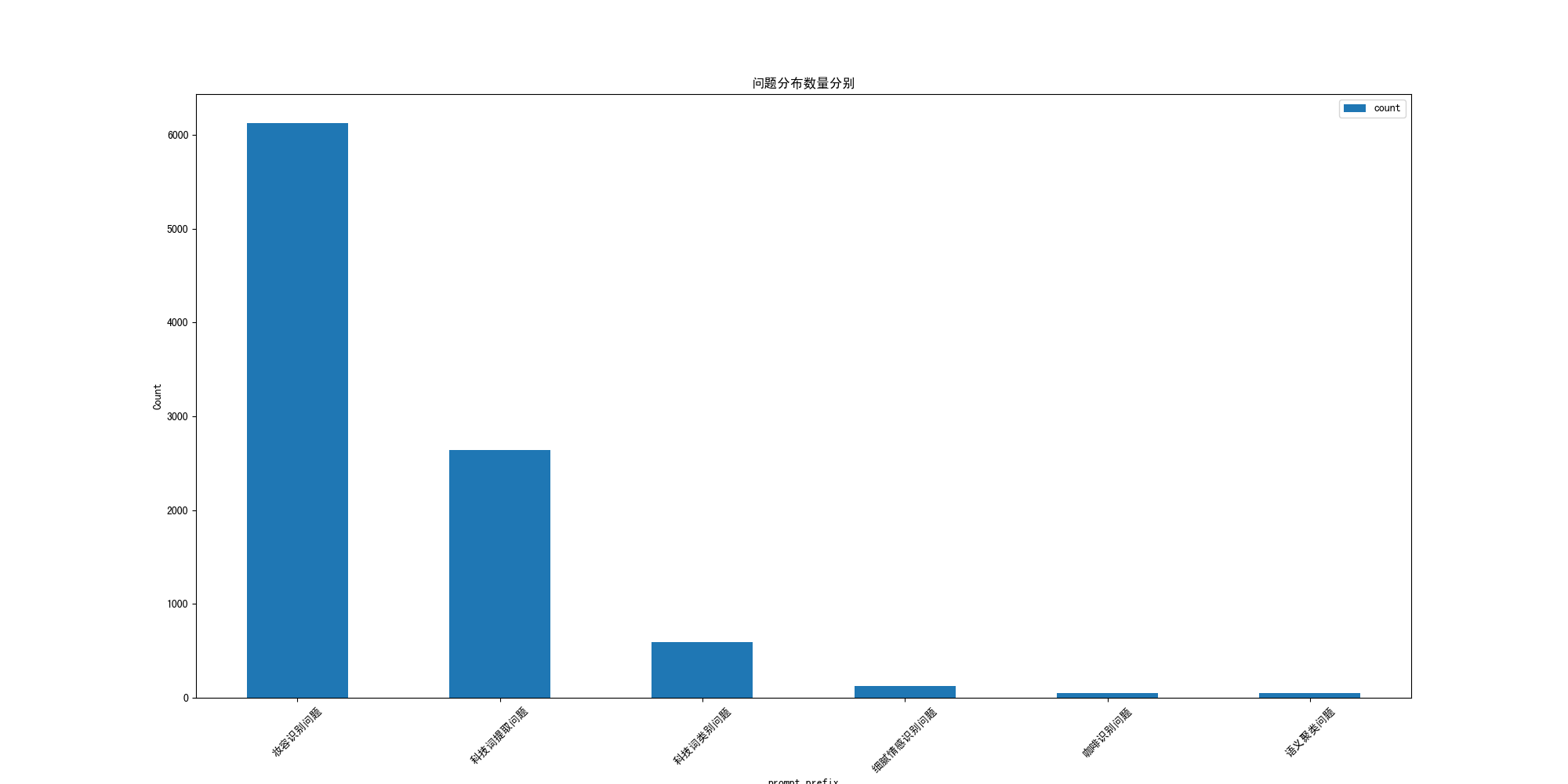
df_prompt_prefix_cnt = df_data['prompt_type'].value_counts().sort_values(ascending=False)
df_counts = df_prompt_prefix_cnt.reset_index()
df_counts.columns = ['prompt_type', 'count']
# 每个token的人民币价格
price_unit = 0.014/1000
#对prompt_type进行groupby,根据groupby的结果对prompt_prefix_len求和,question_len求和,anwser_len求和,prompt_token_num anwser_token_num total_token_num
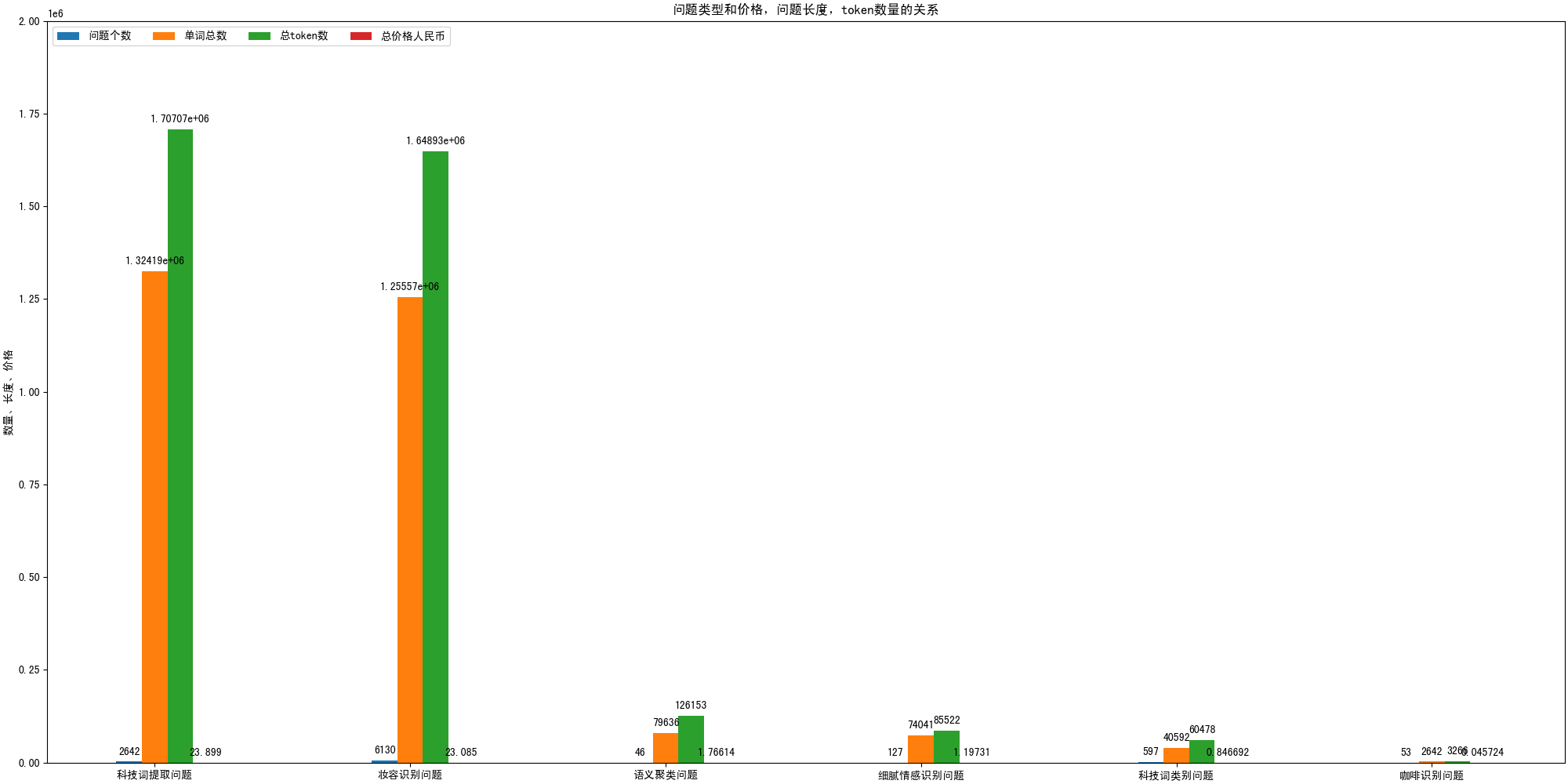
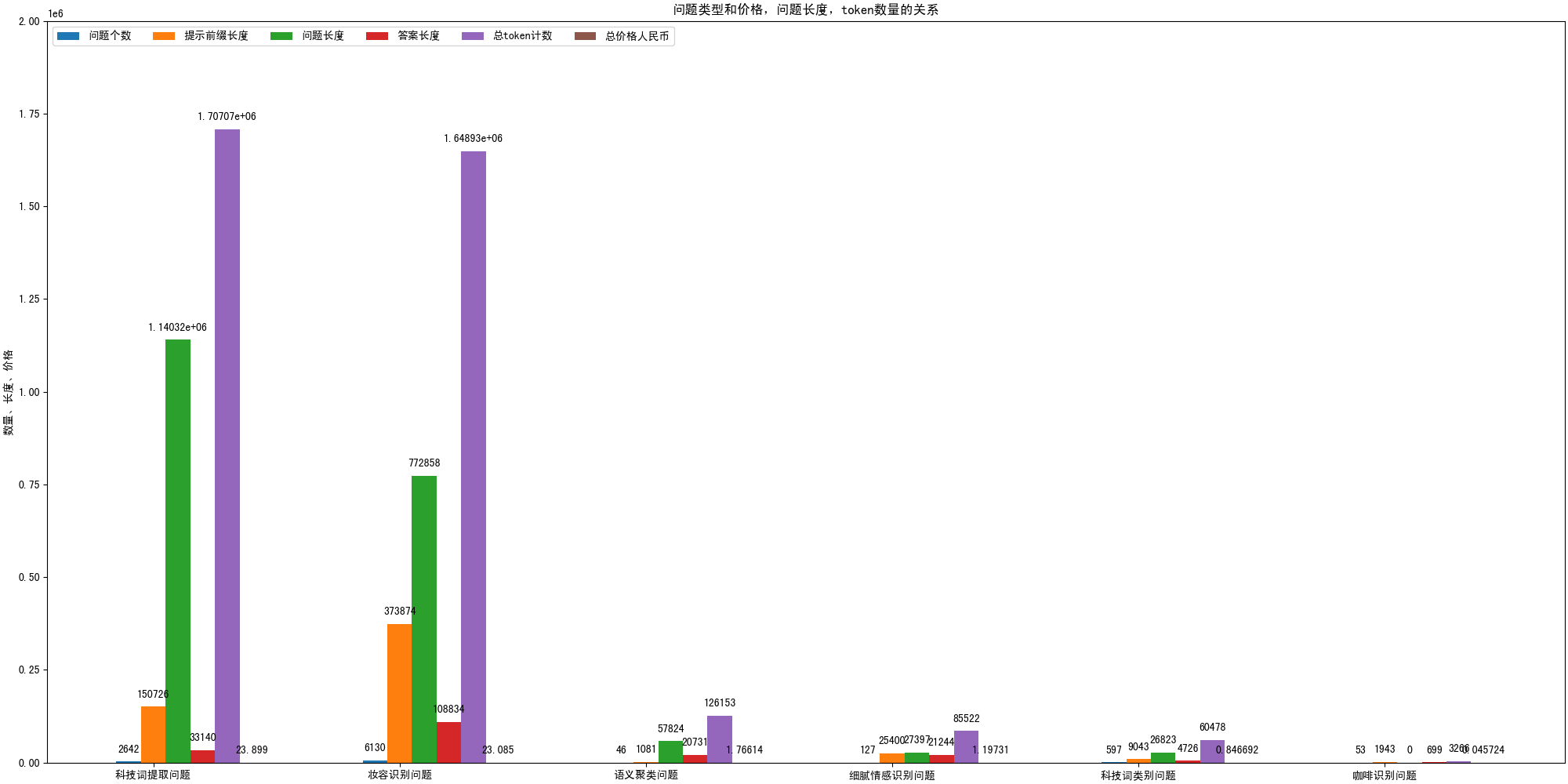
df_sum = df_data.groupby("prompt_type").agg({"total_length": "sum", "total_token_num": "sum"})
df_sum = df_sum.reset_index()
df_sum = df_sum.sort_values(by="total_token_num", ascending=False)
# 加上df_counts中的count列
df_sum = pd.merge(df_sum, df_counts, on="prompt_type", how="left")
# 调换列的顺序,让count列在最前面,去掉"prompt_token_num", "anwser_token_num",
df_sum = df_sum[["prompt_type", "count", "total_length", "total_token_num"]]
# 计算总的价格,根据total_token_num乘以price_unit
df_sum["total_price"] = df_sum["total_token_num"] * price_unit
print(f"形状是{df_sum.shape}")
# 重命名列名, 去掉:"提示token计数", "答案token计数",
df_sum.columns = ["prompt_type", "问题个数", "单词总数", "总token数","总价格人民币"]
df_list = df_sum.to_dict(orient="list")
prompt_types = df_list.pop("prompt_type")
# 其余的列转换成字典,key是列名,值是列表,list
# 绘图
x = np.arange(len(prompt_types)) # the label locations
width = 0.1 # the width of the bars
multiplier = 0
fig, ax = plt.subplots(layout='constrained',figsize=(20, 10), dpi=100)
for attribute, measurement in df_list.items():
offset = width * multiplier
rects = ax.bar(x + offset, measurement, width, label=attribute)
ax.bar_label(rects, padding=5)
multiplier += 1
# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_ylabel('数量、长度、价格')
# 设置标题
ax.set_title('问题类型和价格,问题长度,token数量的关系')
ax.set_xticks(x + width, prompt_types)
ax.legend(loc='upper left', ncols=5)
# 上限200万
ax.set_ylim(0, 2000000)
png_file = "/Users/admin/tmp/question_prices2.png"
plt.savefig(png_file)
print(f"保存到文件{png_file}")
|