Chatgpt分享
ChatGPT运行原理
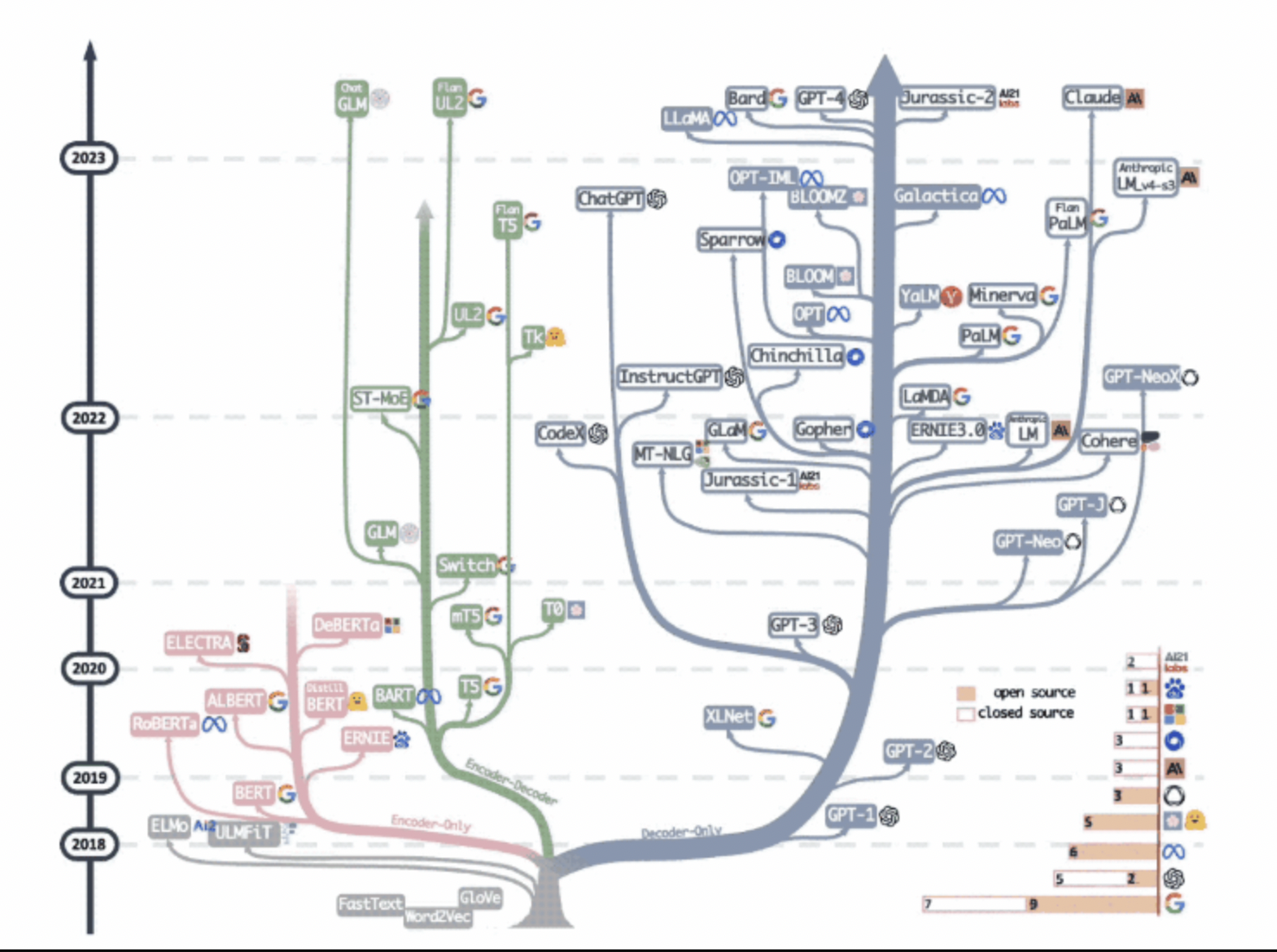
大语言模型进化树:
一共三种方式: 编码器,解码器,编码器-解码器
编码器代表:Bert的训练方式:
完形填空: ___________和阿里、腾讯一起并成为中国互联网 BAT 三巨头。
随机地扣掉一部分字,形成上面例子的完形填空题型,不断地学习空格处到底该填写什么。所谓语言模型的训练和学习,就是从大量的数据中学习复杂的上下文联系。
解码器代表: GPT的训练方式:
根据已有句子的一部分,来预测下一个单词会是什么。
示例:手机上的输入法,它可以根据当前输入的内容智能推荐下一个词。
编码器-解码器Transformer结构: T5,GLM
数据—向量—数据
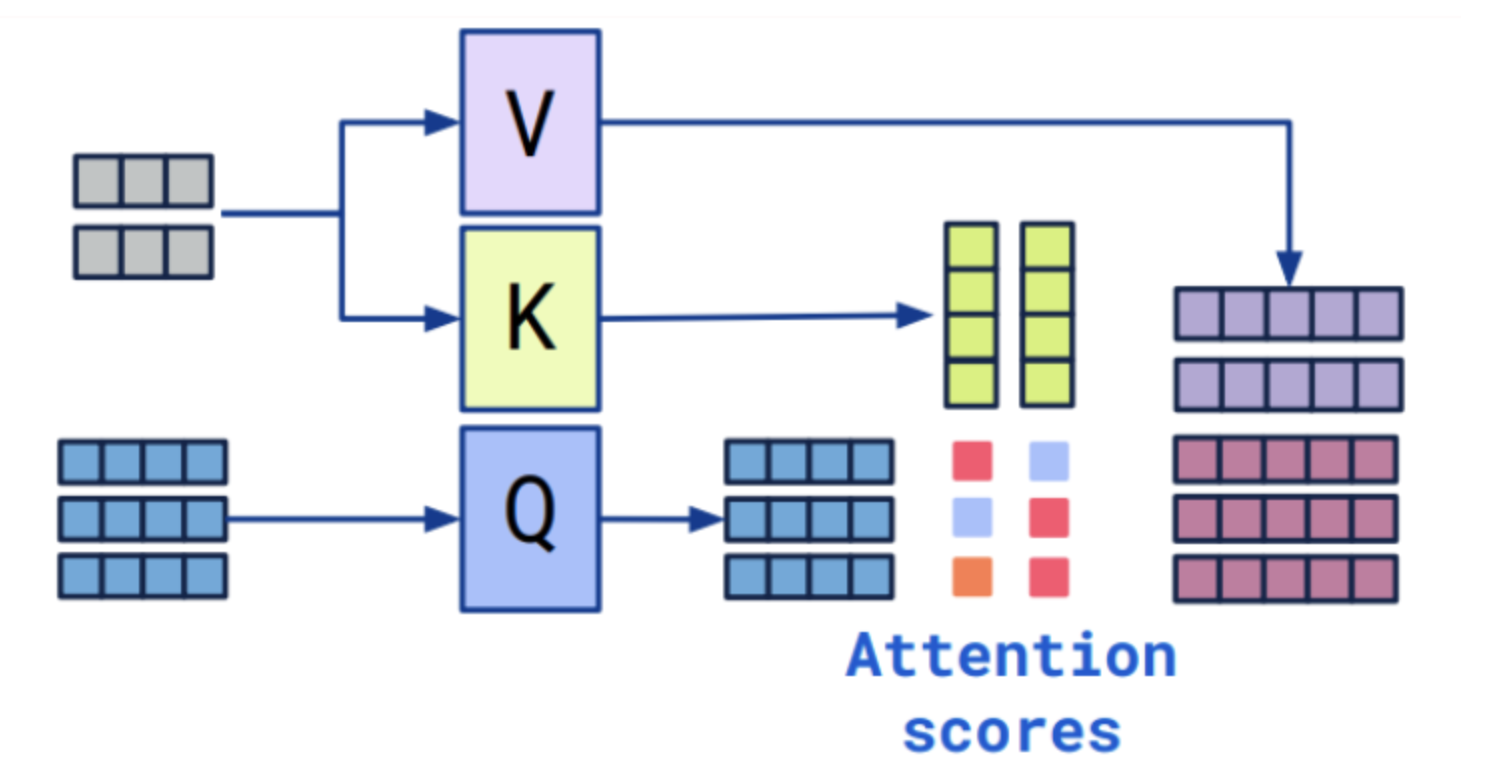
self-attention和cross-attention其实就是比较表面的意思,self-attention可以理解为自我观察学习,cross-attention是借鉴和学习。
把下面这句话当成自己,每个词当成每个生活的部分,相互影响。
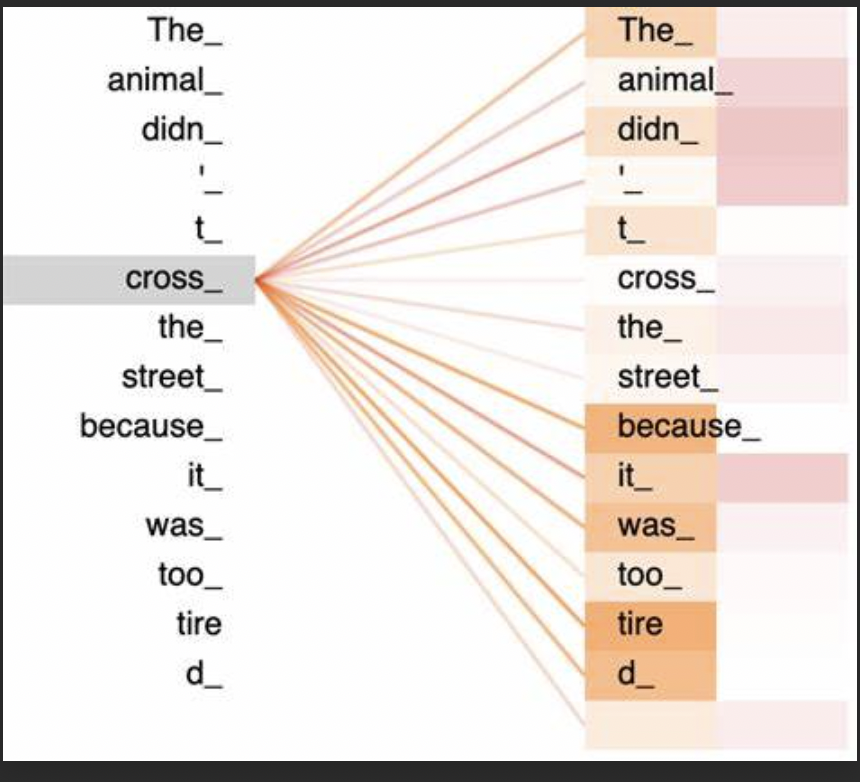
灰色块和蓝色块是来自2个不同的向量,例如2个不同的句子,图片和文本,等等
ChatGPT训练方法
Openai的训练方法:
BaseModel: GPT3.5, 1750亿参数,45TB训练数据
SFT: supervised fine-tuning监督微调模型, 大量标注问答对数据
RM: Reward Model训练一个奖励模型或者叫做偏好模型, 一个问题生成多个答案,人工排序后,RM模型知道哪个答案更好。
RLHF: reinforcement learning from human feedback,人类反馈的强化学习, 对齐AI系统和人类, PPO强化学习算法微调模型SFT,RM反馈,另一个约束是KL散度,即原始当前模型和对比模型的KL散度差。
Actor就是我们的模型,update是对比模型,ENV是RM模型,Reward是RM模型的输出。
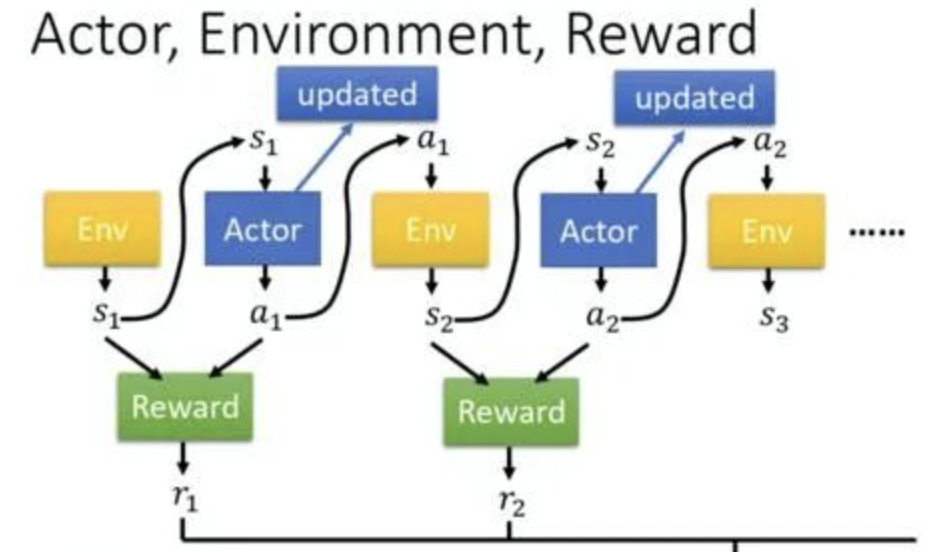
小知识:PPO算法简单理解:Proximal Policy Optimization Algorithms, 如何更新策略,即如何更新决策,这里就是如何更新模型,KL散度简单理解,衡量两个概率分布之间差异的一种度量方式,这里是训练约束2个模型的差异不要太大。
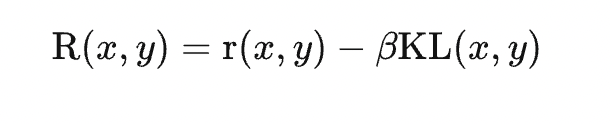
开源的训练方法:
适配器方面,撬动大模型。
Huggingface的PEFT库集成,Parameter-Efficient Fine-Tuning 参数高效微调的方法,总的来说就是对模型的部分参数进行微调
包括4种适配器方法
PROMPT_TUNING
提示优化,额外的文字和占位符向量
P_TUNING,https://zhuanlan.zhihu.com/p/610943594
嵌入优化,V1只训练嵌入向量,V2模型每一层添加一个额外的向量
PREFIX_TUNING
提示学习的前缀优化,输入中添加k个位置,注意力层添加对这个k个位置的注意力向量。
LORA: https://zhuanlan.zhihu.com/p/610943445
来自微软的Low-rank论文,对注意力中的q和v进行添加,低秩矩阵参数量小,降低微调时的计算复杂度和内存消耗
例如训练roberta-large时,使用LoRA微调月10GB显存,总的参数量是3.5亿,其中训练参数是0.5%,其它冻结
如果全部微调,那么使用的显存是18GB
数据方面:
借助ChatGPT生成数据, 斯坦福大学不到 500 美元,使用Facebook开源的LLaMA进行微调。
https://github.com/tatsu-lab/stanford_alpaca
instruction: 描述了模型应该执行的任务,共52K指令
input: 任务的可选上下文或输入,可以为空
output: chatgpt生成的答案
模型方面:
Base模型:Facebook的LLama模型,bigScience的Bloom, 清华的GLM
其它模型,有的是微调模型,有的是其它版本模型:Dolly,ChatYuan,ChatGLM-6B,MOSS,RWKV-LM,stanford_alpaca,Chinese-alpaca-lora,Vicuna,Colossal AI,BELLE,Firefly,Phoenix
训练技术方面: 撬动大模型。
混合精度和分布式训练
模型的大小由其参数量及其精度决定,精度通常为 float32、float16 或 bfloat16, huggingface的LLM.int8() 方案
小知识:1个字节(Byte)等于8个位(bit),即8个二进制数字,每个二进制数字可以表示0或1两种状态,所以FP32占4个字节,int8占1个字节。GLM-6B举例,如果模型使用fp16,全部微调模型,每个参数占大概2个字节,Adam优化器需要8个字节, 6010100000000/1024/1024/1024=55.9GB, 加上一些其它并且还可能需要更多用于计算诸如注意力分数的中间值。
https://zhuanlan.zhihu.com/p/624929178
分布式训练: 模型并行,数据并行,张量并行
工具库和显存优化算法:
accelerate,torchrun,DeepSpeed
新技术:
LangChain: 字面意义,链接模型,数据,和提示链,一个提示接着一个提示。
Auto-GPT: 任务分解,将任务分解多个步骤,并对每个步骤进行分析和决策
minigpt-4: 多模态的gpt问答
imagebind: meta开源,6模态,图像、文本、音频、深度、温度和 IMU 数据
图像领域: Segment Anything, stable diffusion, Control Net
ChatGPT的优缺点
优点:更智能,更通用
缺点:容易胡说,专业度差, 推理能力差,不能真正的实时学习
术语
CoT: Chain-of-Thought,链式思考(CoT),加上“让我们逐步思考”,增加模型的推理能力
EA: 涌现能力(Emergent Ability),指的是当模型参数规模未能达到某个阀值时,模型基本不具备解决此类任务的任何能力,体现为其性能和随机选择答案效果相当,但是当模型规模跨过阀值,LLM模型对此类任务的效果就出现突然的性能增长。
AIGC:AI Generated Content ,人工智能自动生成内容
NLP:Natural Language Processing,自然语言处理
LLM:Large language model,大语言模型
AGI:Artificial general intelligence,通用人工智能
Prompt:提示词
Fine-tuning:模型调优
ML:Machine Learning,机器学习
DL:Deep Learning,深度学习
BERT:Bidirectional Encoder Representations from Transformers”,双向编码器表示
RLHF:Reinforcement Learning from Human Feedback,基于人类反馈的强化学习