领域内问答分享
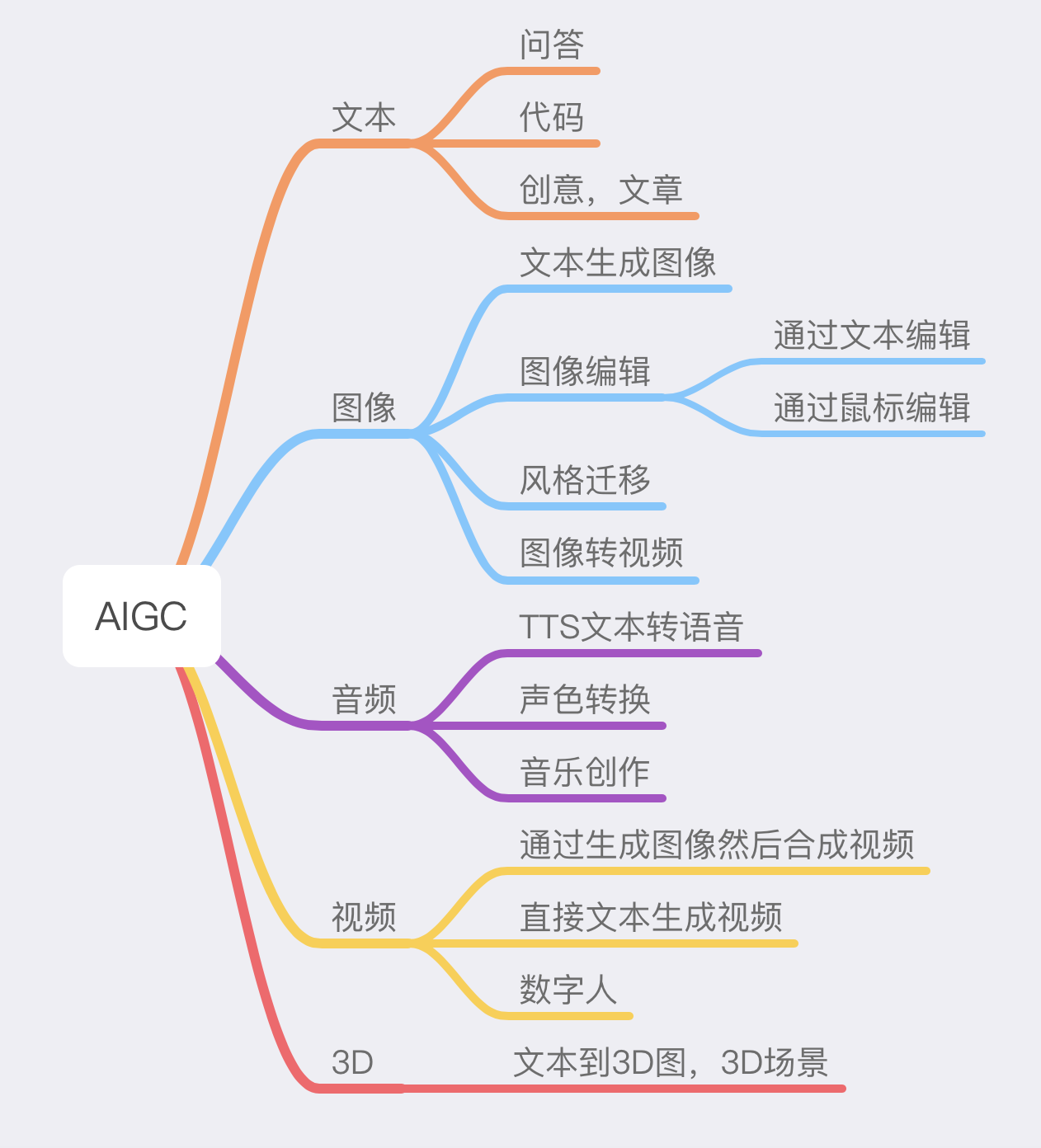
AIGC
AIGC在各种方面的应用
领域内问答的是如何实现的
数据集来源
A. 内部平台使用教程
B. 行业报告,白皮书等
C. 美妆专业知识
D.所有用户(客户,内部人员)常见问题收集
不同数据集不同对待,完全训练,微调和提示工程
对于从0开始学习的大模型来说,最好的方式是完全训练。
完全训练:针对大公司有超多数据集和计算资源,可以采用完全训练的方式。
对于基础的专业知识来说,最好的方式是微调训练。
微调训练:基于大模型的二次训练。主要使用的方法是使用开源大模型,例如
Base模型:Facebook的LLama模型,bigScience的Bloom, 清华的GLM等,借助工具库和显存优化算法accelerate,torchrun,DeepSpeed,采用适配器的方式进行微调,典型的包括Huggingface的PEFT库集成,Parameter-Efficient Fine-Tuning 参数高效微调的方法。
对于部分专业文档问答,教程来说,最好的方式是提示工程,现学现用的方式。
LLM中的推理生成流程
输入
历史聊天和最新问题会转成如下格式进行tokenizer
例如历史聊天记录为Round 0部分,Round 1 为最新的问题,拼接历史和最新的聊天作为输入:
1 | |
Tokenizer
文字经过tokenizer,进行拆词变成input id
输入模型generate函数
重要参数:
inputs:输入的input id,其实还可以语音到文本,图片到本文,都可以。
logits_processor:对预测出来的下一个logits的处理,例如使用temperature,topk,topp,或用户对logits进行自定义处理等
stopping_criteria: 停止生成的条件,例如遇到了EOS的token或用户指定token,或达到最大长度等等。
is_encoder_decoder:是解码器还是编码器-解码器架构
While True:
准备input_id
模型前向传播
获取模型返回的logits
对logits进行处理,例如temperature,topk等
softmax和Sample token,得到next token id
更新input_id
判断停止生成条件,如果没有继续生成,否则break
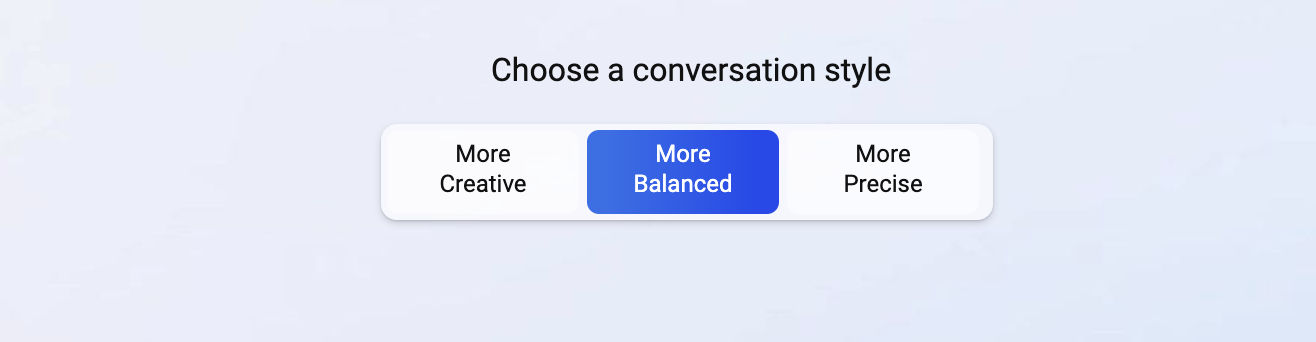
LLM中使用的超参数
对应着New bing中的对话风格。
创作,平衡和准确,意味着temperature的不同。
Langchain
集成了最新的使用LLM进行解决复杂问题的方法。Langchain是链式调用工具,整合数据处理,数据调用,提示工程,LLM调用,输出格式化,复杂链式调用等技术,是自然语言和程序之间进行交互的胶水,由语言模型驱动的应用程序的框架,数据感知:将语言模型连接到其他数据源,Agentic:允许语言模型与其环境交互。
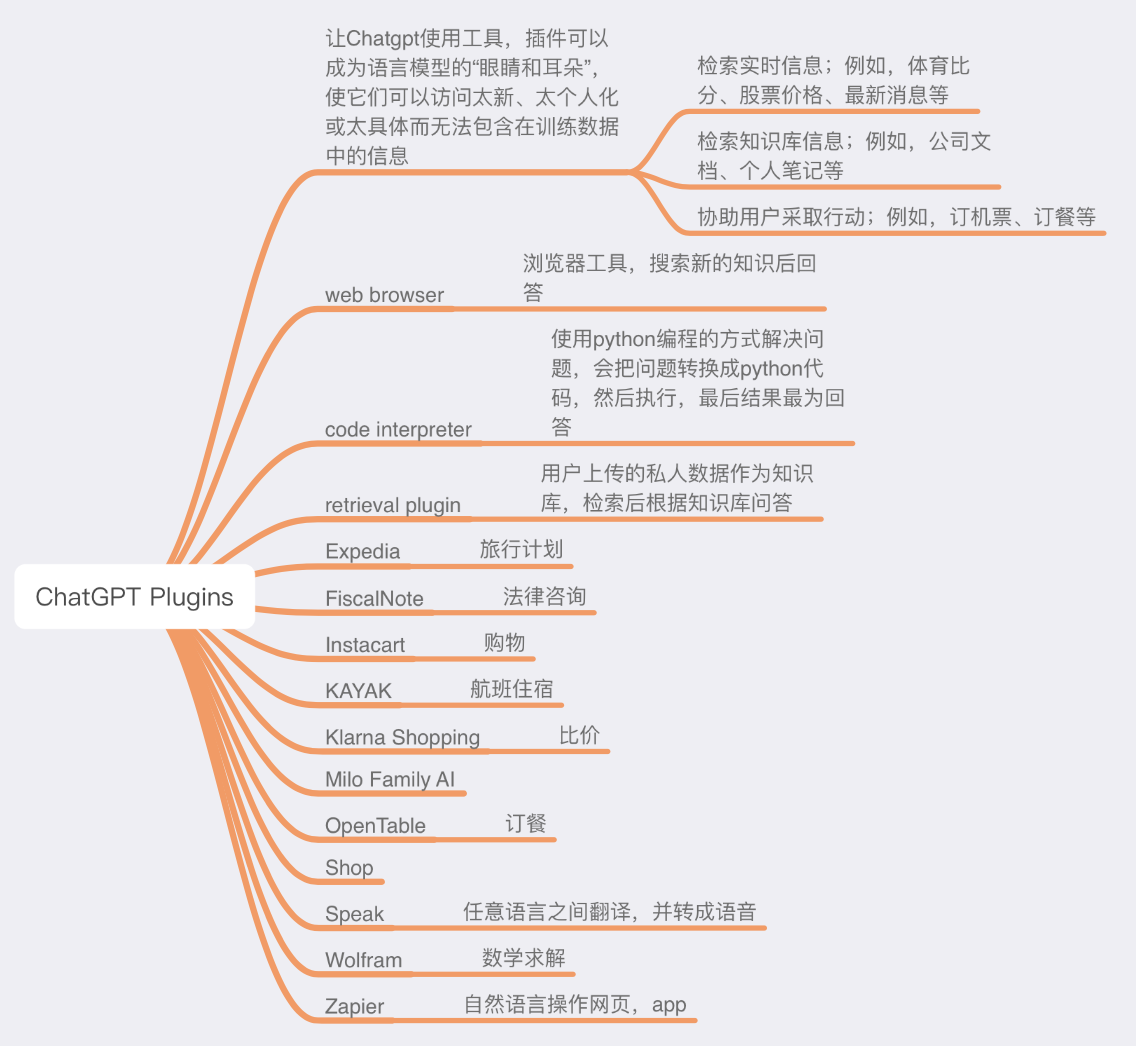
ChatGPT的plugins和LangChain的Tools
ChatGPT Plugins
让Chatgpt使用工具,插件可以成为语言模型的“眼睛和耳朵”,使它们可以访问太新、太个人化或太具体而无法包含在训练数据中的信息
检索实时信息;例如,体育比分、股票价格、最新消息等
检索知识库信息;例如,公司文档、个人笔记等
协助用户采取行动;例如,订机票、订餐等
LangChain tools
Agent可以采取的行动,可以定制化开发。有工具tool和工具包toolkits两种概念,工具包就是多个工具的一起协作。工具的类型和Chatgpt的Plugin是一样的。但是工具更多。