混合精度训练的细节
精度的前提知识
1B(Byte)字节=8bit比特,位

FP32
使用32位二进制格式来表示实数。
可以表示的数字范围更广,精度更高。
在大多数应用中被广泛使用,因为它提供了足够的精度和数字范围。
硬件支持程度广泛,几乎所有现代CPU和GPU都支持FP32。
FP16
也叫half,半精度
FP16是16位浮点数格式,FP32是32位浮点数格式。
使用16位二进制格式来表示实数。
可以表示的数字范围比较小,但是精度相对较低。
在深度学习等计算密集型任务中,使用FP16可以大大减少内存使用,加快计算速度。
硬件支持程度有限,一些较旧的GPU可能不支持FP16。
BFloat16
BFloat16是一种浮点数格式,它用于表示16位二进制浮点数。它的名称来自于"Brain Floating Point format",因为它是由谷歌公司的Brain团队开发的。与传统的浮点数格式(如IEEE 754)相比,BFloat16使用更少的位数来表示一个浮点数,这在机器学习和人工智能等计算密集型应用中非常有用,因为它可以减少内存使用和加速计算。
BFloat16的格式是1位符号位、8位指数和7位尾数。它可以表示的范围和精度与IEEE 754单精度浮点数(32位)相似,但是它不能表示与IEEE 754双精度浮点数(64位)相同的精度和范围。BFloat16广泛应用于机器学习框架和芯片设计中,例如TensorFlow和Google的TPU芯片。
可以表示的数字范围比较小,但是相对于FP16而言精度更高。
在TensorFlow和Google的TPU芯片等机器学习框架和芯片中广泛使用。
可以用于进行混合精度计算,其中权重和梯度使用FP32或更高精度的浮点数,而激活使用BFloat16,从而提高计算速度和减少内存使用。
使用16位二进制格式来表示实数,其中5位用于指数,10位用于尾数,1位用于符号。
可以表示的数字范围和精度相对于BFloat16而言略低。
在深度学习等计算密集型任务中,使用FP16可以大大减少内存使用,加快计算速度。
可以用于进行混合精度计算,从而提高计算速度和减少内存使用。
BFloat16相对于FP16而言精度更高,但是支持程度较低,而FP16则具有更广泛的支持程度,但是精度略低
相对于FP16,失去了3比特的精度
int8
FP32被称为全精度(4字节),而BF16和FP16被称为半精度(2字节)。在此基础上,int8(INT8)数据类型由8字节表示组成,可以存储2^8个不同的值(对于有符号的整数,在[0,255]或[-128,127]之间)
如果模型是1760亿参数,用半精度推理,那么需要的GPU内存是1760亿* 2byte = 352GB
BLOOM-1760亿参数需要8个80GB的A100进行推理, 如果微调,需要72个
GPU设备上加载一个模型,每十亿个参数在float32精度下要花费4GB,float16要花费2GB,int8要花费1GB
如果你使用AdamW优化器,每个参数需要8个字节,10亿个参数需要8GB的GPU内存
Huggingface 的LLM.int8()
使用LLM.int8()的BLOOM-176B比fp16版本慢了大约15%到23%
int4
等价4bit训练
NVIDIA的图灵Turing架构
推理速度更快,精度损失较小,约1%
工作原理
通过“量化”的 FP32 模型运行校准数据集并收集直方图数据
使用直方图查找所有张量的第 99.999 个百分位数范围值
使用新范围调整模型中的量化层
通过量化模型运行训练数据集的一个时期,并使用量化层的直通估计器 Straight Through Estimator (STE) 反向传播误差。继续训练,直到准确度达到可接受的水平。
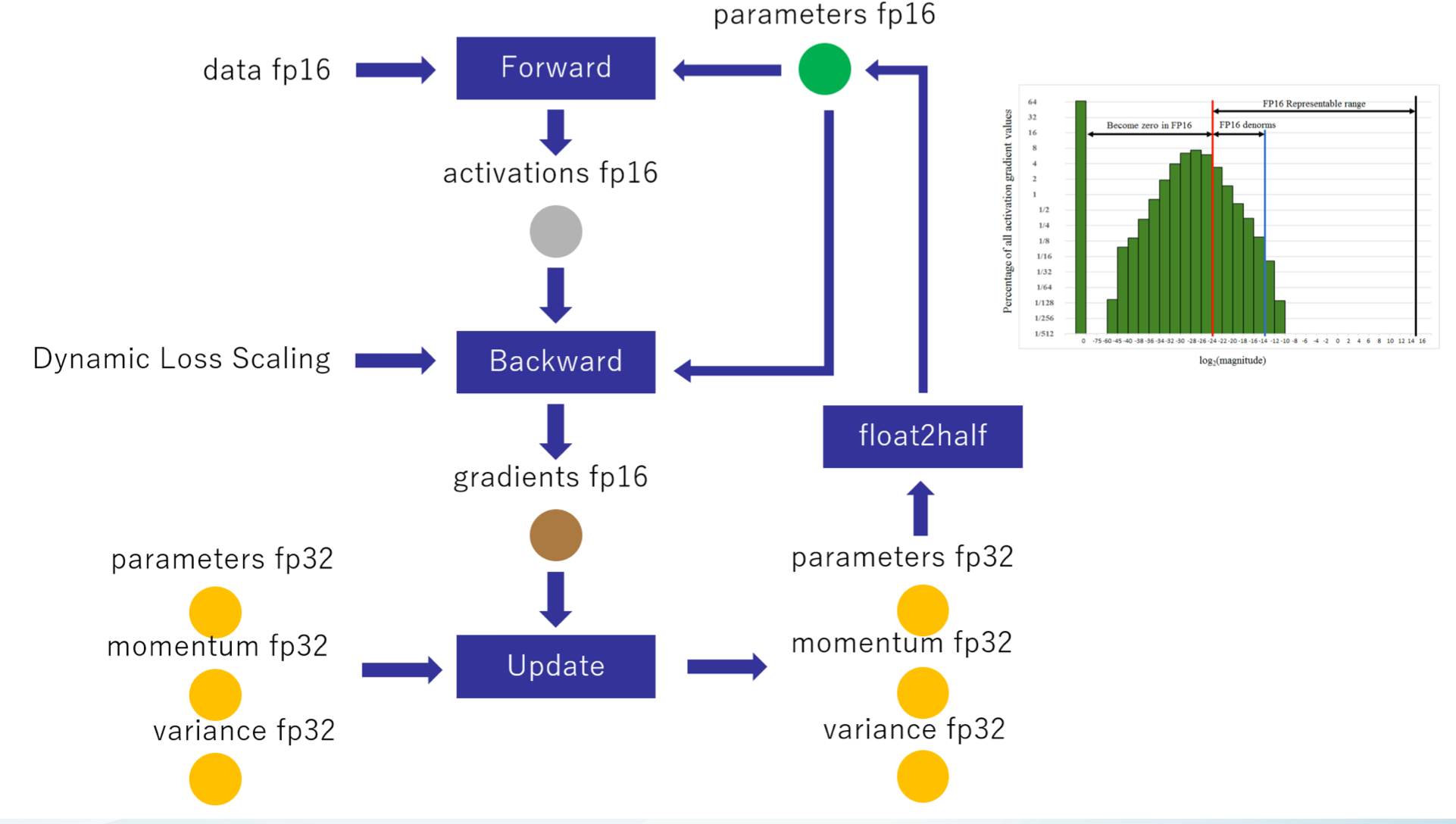
混合精度训练(mixed precision training)
Adam 在 SGD 基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)。混合精度训练,字如其名,同时存在 fp16 和 fp32 两种格式的数值,其中模型参数、模型梯度都是 fp16,此外还有 fp32 的模型参数,如果优化器是 Adam,则还有 fp32 的 momentum 和 variance。
过程:数据,前向模型参数,激活,梯度都用fp16,反向传播更新参数时,使用预先备份的模型32位参数,优化器的32位动量和二阶动量32位参数进行更新模型参数,更新后的模型参数进行进行fp16前向传播
ZeRO简介
微软的 DeepSpeed 团队解决数据并行的中存在的内存冗余问题所提出的解决方法,安装deepspeed库即可使用。
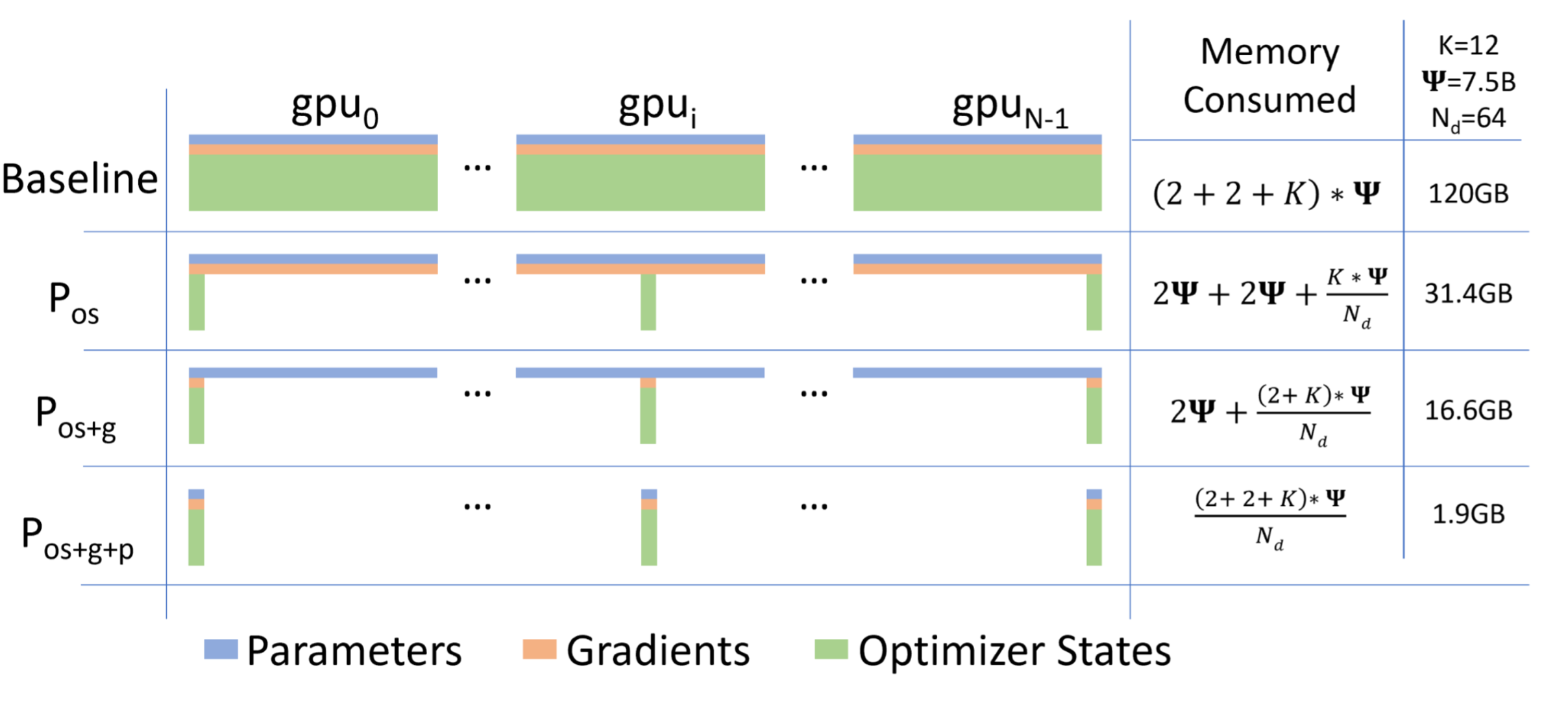
思路:常驻在每块GPU上的数据可以分为三部分:模型参数,模型梯度和优化器参数。注意到由于每张 GPU 上都存储着完全相同的上述三部分参数,我们可以考虑每张卡上仅保留部分数据,其余的可以从其他 GPU 上获取。
下图表示当对模型参数,梯度,和优化器状态分别进行分割存储后,占用显存量的多少的对比。
混合精度训练的细节
https://johnson7788.github.io/2023/05/25/%E6%B7%B7%E5%90%88%E7%B2%BE%E5%BA%A6%E8%AE%AD%E7%BB%83%E7%9A%84%E7%BB%86%E8%8A%82/