几种模型回答同一问题的对比
9款模型对比模型vicuna7B,13B, glm6B, Chinese Lamma7B,13B,chatgpt,gpt4,rwkv,基于Bloom的Belle
gradio写了一个简单的测试接口
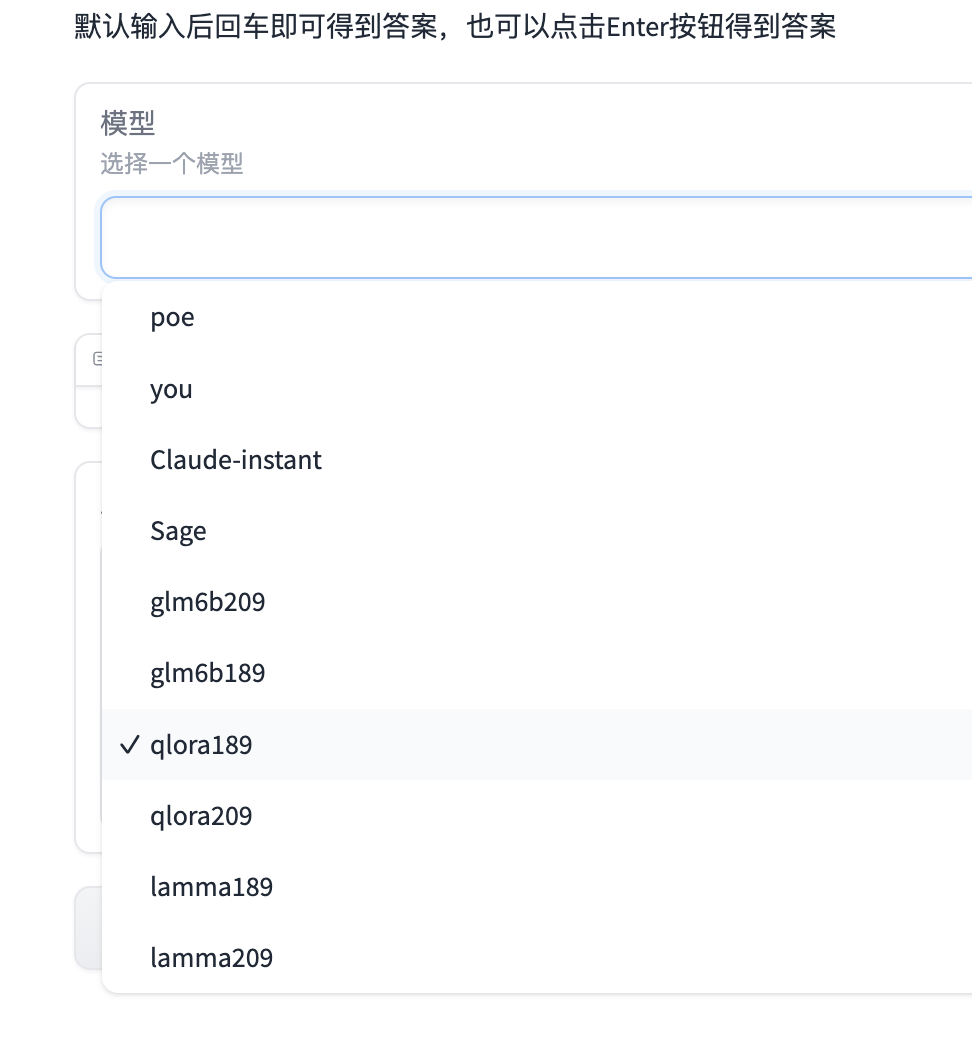
问题: 防晒霜的使用顺序?
1.清华大学glm6B模型
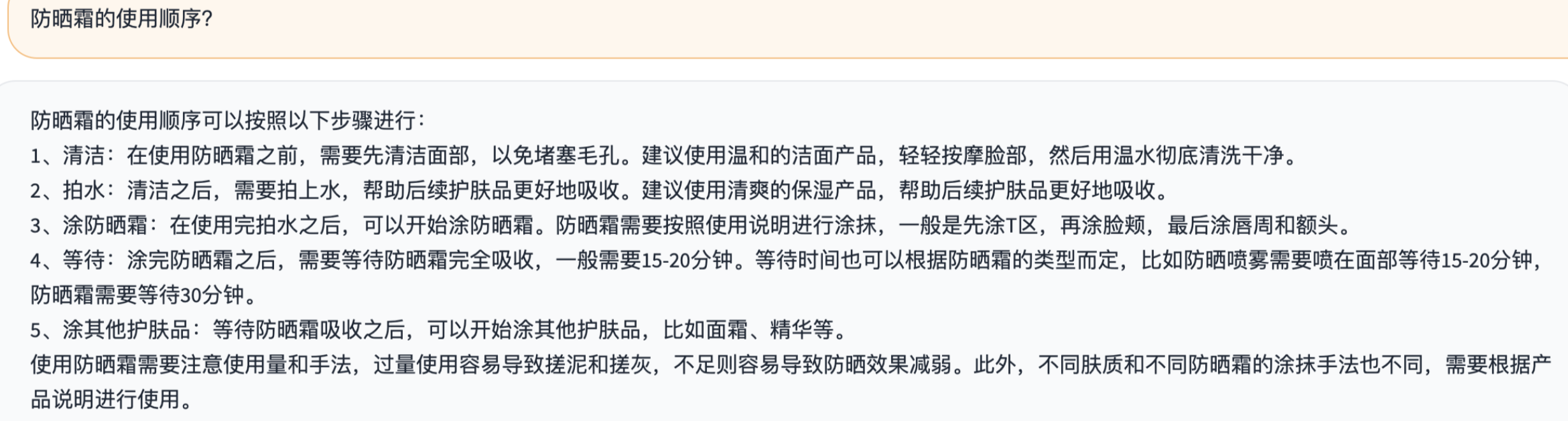
2.斯坦福大学的vicuna7B模型
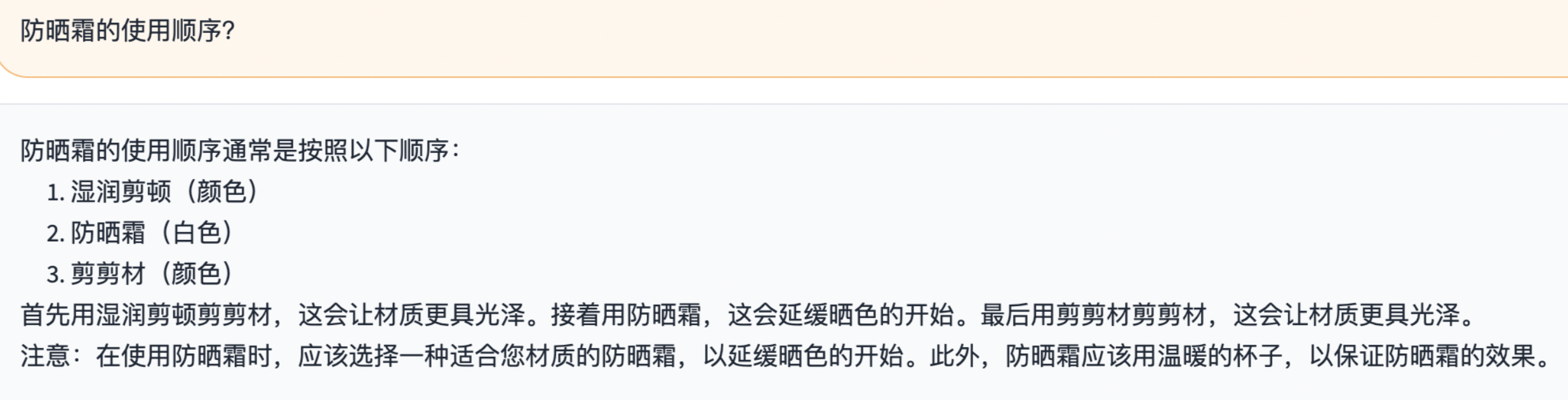
3.斯坦福大学的vicuna13B模型
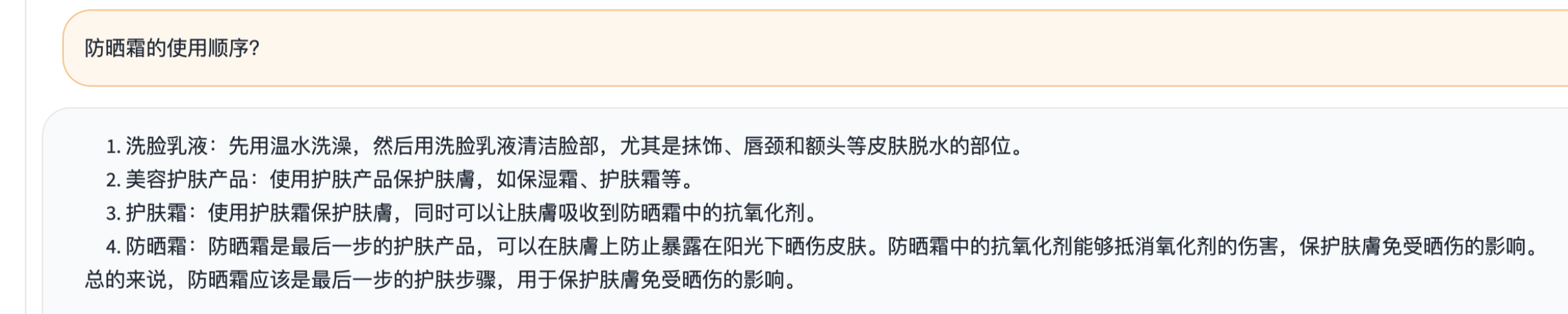
4.哈工大的lamma 7B

5.哈工大的lamma13B
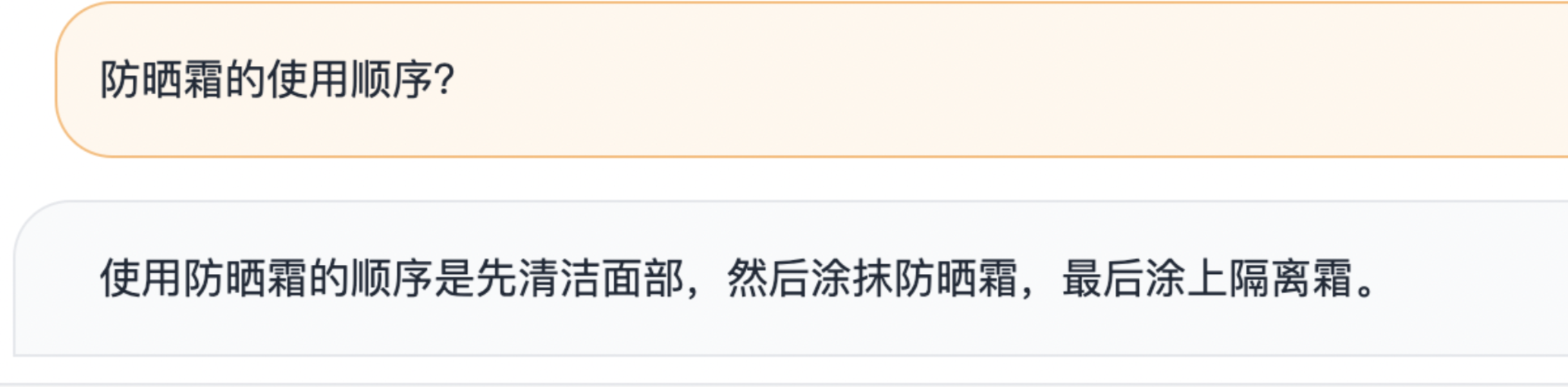
6.chatgpt
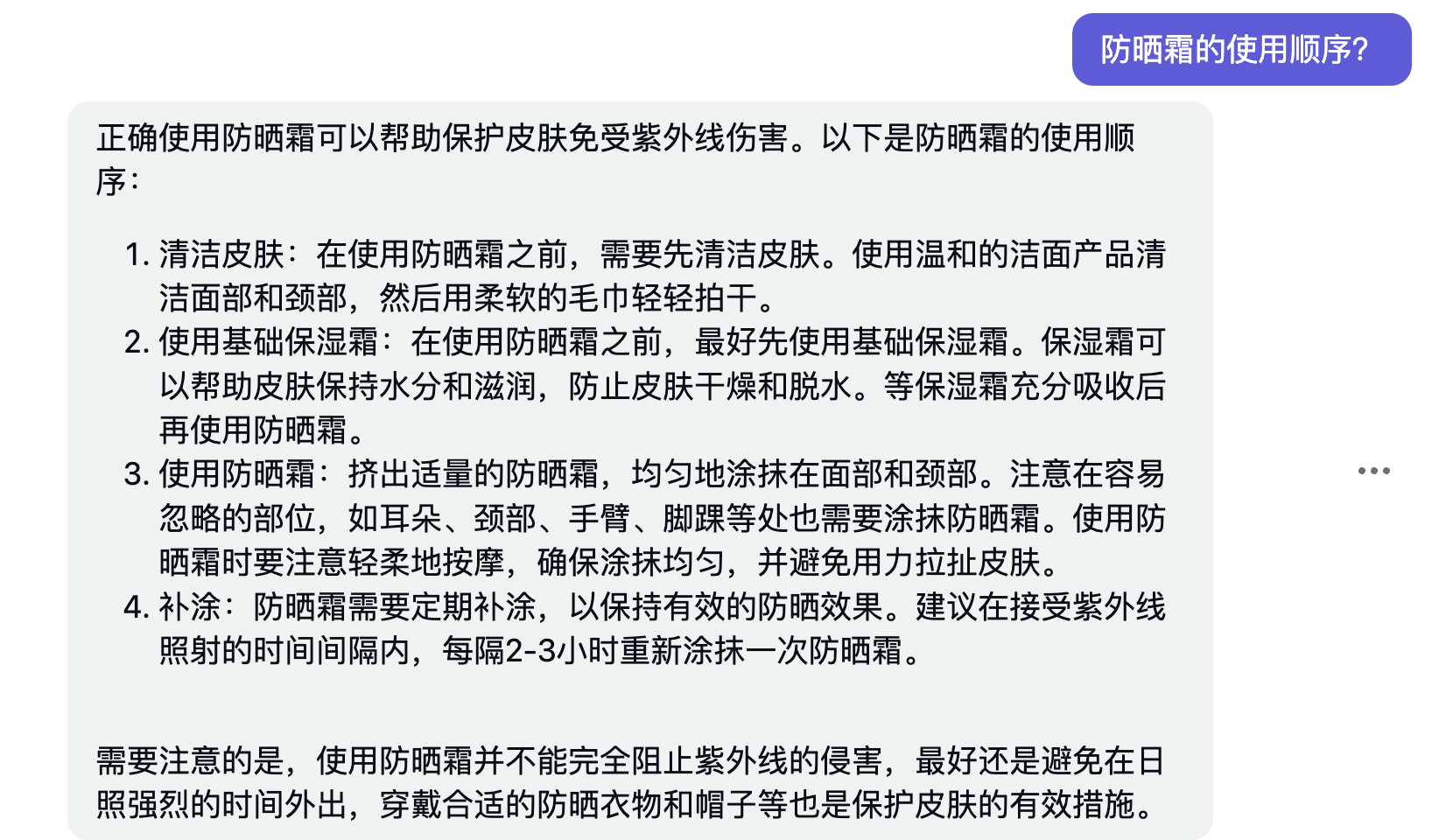
7.Gpt4

8.RWKV:回答的也是驴唇不对马嘴😂

- 经过微调的Bloom模型,BELLE-7B-2M

结论
综合来看斯坦福的vicuna模型7B效果最差,其次是13B,缺少对中文语料的训练,所以导致对中文理解较差,哈工大的Lamma 7B弱于13B,哈工大的13B和glm6B效果差不太多,但都弱于Chatgpt ,gpt4效果最好。
几种模型回答同一问题的对比
https://johnson7788.github.io/2023/06/15/%E5%87%A0%E7%A7%8D%E6%A8%A1%E5%9E%8B%E5%9B%9E%E7%AD%94%E5%90%8C%E4%B8%80%E9%97%AE%E9%A2%98%E7%9A%84%E5%AF%B9%E6%AF%94/