1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
| """
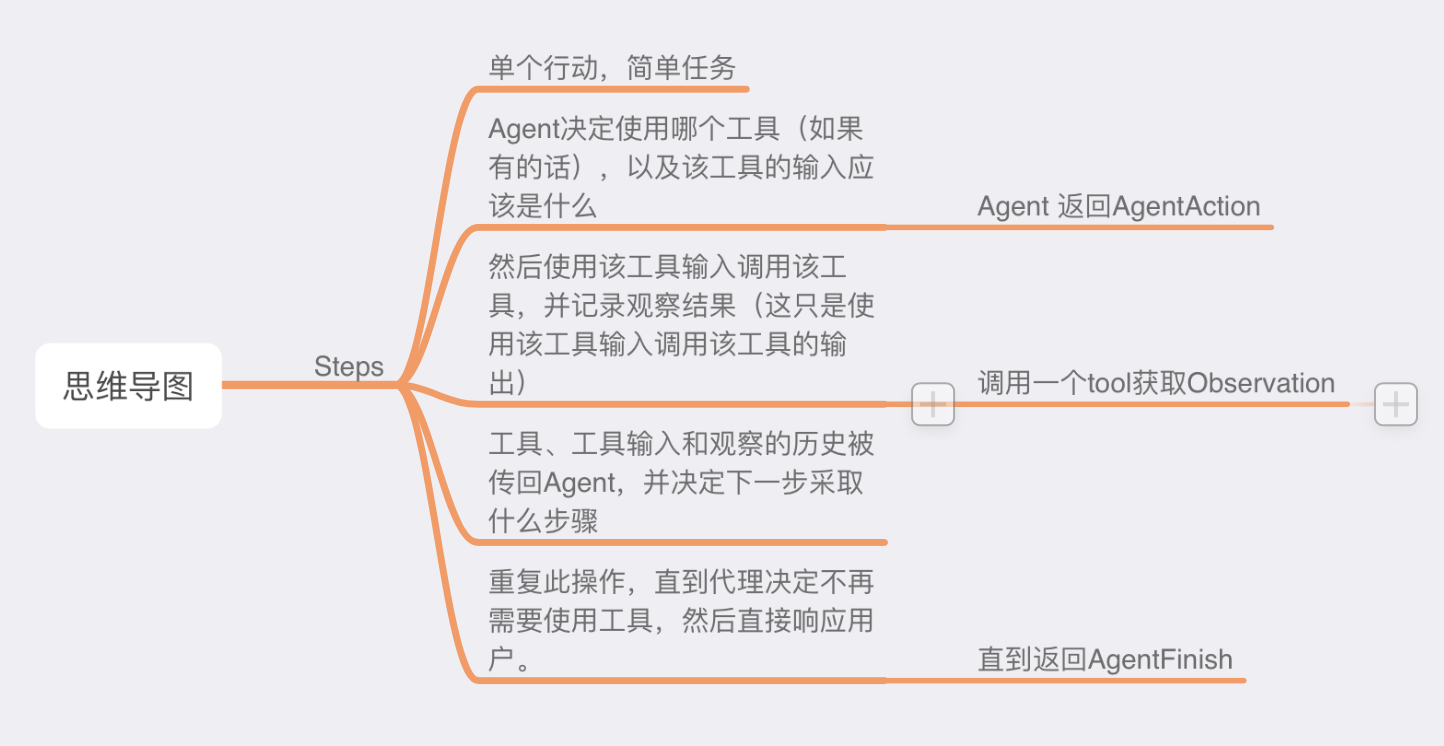
1. 解决了LLM在执行Thought时回复ActionAgect的Observation导致后续干扰的问题
2. 取代LLM设定plan,自行给问题设定解决计划
3. 解决LangChain执行完成所有steps,只用最后一个step答案作为最终答案。应该用每个steps的答案进行汇总
"""
from langchain.experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
from langchain import PromptTemplate, OpenAI, LLMChain
from langchain import SerpAPIWrapper
from langchain.agents.tools import Tool
from langchain import LLMMathChain
from chat.LLMapi import YouAPI,PoeChatGPTAPI
from typing import List
from langchain.agents.agent import AgentExecutor
from langchain.agents.structured_chat.base import StructuredChatAgent
from langchain.base_language import BaseLanguageModel
from langchain.experimental.plan_and_execute.executors.base import ChainExecutor
from langchain.tools import BaseTool
from typing import Any, Dict, List
from typing import Optional, Union
from pydantic import Field
from langchain.callbacks.manager import CallbackManagerForChainRun
from langchain.chains.base import Chain
from langchain.experimental.plan_and_execute.executors.base import BaseExecutor
from langchain.experimental.plan_and_execute.planners.base import BasePlanner
from langchain.experimental.plan_and_execute.schema import (
BaseStepContainer,
ListStepContainer,
)
from langchain.schema import AgentAction, AgentFinish, OutputParserException
from langchain.experimental.plan_and_execute.schema import (
Plan,
PlanOutputParser,
Step,
)
from langchain.agents.structured_chat.output_parser import StructuredChatOutputParserWithRetries
def search(query: str) -> str:
"""
Args:
query ():
Returns:
"""
if query == "Who is Leo DiCaprio's girlfriend?":
result = "DiCaprio broke up with girlfriend Camila Morrone, 25, in the summer of 2022, after dating for four years. He's since been linked to another famous supermodel – Gigi Hadid. The power couple were first supposedly an item in September after being spotted getting cozy during a party at New York Fashion Week."
elif query == "What is Gigi Hadid's current age?":
result = "Gigi Hadid is 28 years old."
elif query == "How old is Gigi Hadid in 2023":
result = "Gigi Hadid is 28 years old."
elif "age" in query or "old" in query:
result = "Gigi Hadid is 28 years old."
else:
result = "search nothing about your question"
return result
llm = PoeChatGPTAPI(temperature=0)
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
),
]
HUMAN_MESSAGE_TEMPLATE = """Previous steps: {previous_steps}
Current objective: {current_step}
{agent_scratchpad}"""
TASK_PREFIX = """{objective}
"""
class MyStructuredChatOutputParserWithRetries(StructuredChatOutputParserWithRetries):
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
try:
if self.output_fixing_parser is not None:
parsed_obj: Union[
AgentAction, AgentFinish
] = self.output_fixing_parser.parse(text)
else:
parsed_obj = self.base_parser.parse(text)
llm_response_log = parsed_obj.log
if "Observation:" in llm_response_log:
llm_response_log = llm_response_log.split("Observation:")[0]
if isinstance(parsed_obj, AgentAction):
parsed_obj = AgentAction(
tool = parsed_obj.tool,
tool_input=parsed_obj.tool_input,
log = llm_response_log,
)
else:
parsed_obj = AgentFinish(
log = llm_response_log,
return_values = parsed_obj.return_values,
)
return parsed_obj
except Exception as e:
raise OutputParserException(f"Could not parse LLM output: {text}") from e
def load_agent_executor(
llm: BaseLanguageModel,
tools: List[BaseTool],
verbose: bool = False,
include_task_in_prompt: bool = False,
max_iterations: Optional[int] = 2,
) -> ChainExecutor:
input_variables = ["previous_steps", "current_step", "agent_scratchpad"]
template = HUMAN_MESSAGE_TEMPLATE
if include_task_in_prompt:
input_variables.append("objective")
template = TASK_PREFIX + template
output_parser = MyStructuredChatOutputParserWithRetries.from_llm(llm=llm)
agent = StructuredChatAgent.from_llm_and_tools(
llm,
tools,
human_message_template=template,
input_variables=input_variables,
output_parser=output_parser,
)
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent, tools=tools, verbose=verbose, max_iterations=max_iterations
)
return ChainExecutor(chain=agent_executor)
class PlanAndExecute(Chain):
llm: BaseLanguageModel
plan_steps: Plan
executor: BaseExecutor
step_container: BaseStepContainer = Field(default_factory=ListStepContainer)
input_key: str = "input"
output_key: str = "output"
@property
def input_keys(self) -> List[str]:
return [self.input_key]
@property
def output_keys(self) -> List[str]:
return [self.output_key]
def final_anwser_prompt(self) -> str:
"""
用于最后生成答案的prompt
Returns:
"""
prompt_template = """Please answer the following question by flowing the context below:
CONTEXT: {context}
QUESTION: {question}
ANSWER:
"""
prompt = PromptTemplate.from_template(prompt_template)
return prompt
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Dict[str, Any]:
if run_manager:
run_manager.on_text(str(plan_steps), verbose=self.verbose)
for step in plan_steps.steps:
_new_inputs = {
"previous_steps": self.step_container,
"current_step": step,
"objective": inputs[self.input_key],
}
new_inputs = {**_new_inputs, **inputs}
response = self.executor.step(
new_inputs,
callbacks=run_manager.get_child() if run_manager else None,
)
if run_manager:
run_manager.on_text(
f"*****\n\nStep: {step.value}", verbose=self.verbose
)
run_manager.on_text(
f"\n\nResponse: {response.response}", verbose=self.verbose
)
self.step_container.add_step(step, response)
prompt = self.final_anwser_prompt()
llm_chain = LLMChain(llm=self.llm, prompt=prompt,verbose=self.verbose)
every_step_response = ""
for step in self.step_container.steps:
every_step_response += step[-1].response + "\n"
final_anwser = llm_chain.predict(question=inputs[self.input_key],context=every_step_response)
return {self.output_key: final_anwser}
def build_plan_steps(steps):
step_list = []
for step in steps:
one_step = Step(value=step)
step_list.append(one_step)
plan_steps = Plan(steps=step_list)
return plan_steps
question_SOP = [
{
"question": "Who is Leo DiCaprio's girlfriend? and how old is she?",
"steps": [
"Who is Leo DiCaprio's girlfriend?",
"how old is her current age?",
]
}
]
executor = load_agent_executor(llm, tools, verbose=True,max_iterations=2)
for info in question_SOP:
question = info["question"]
steps = info["steps"]
plan_steps = build_plan_steps(steps)
agent = PlanAndExecute(llm=llm,plan_steps=plan_steps, executor=executor, verbose=True)
result = agent.run(question)
print(result)
|