世界模型
世界模型和I-JEPA
什么是世界模型
- Meta AI的首席人工智能科学家Yann LeCun,图灵奖获得者,提出的一种模型结构。
- 世界模型是自主智能架构,能够模拟世界运作方式的人工智能,人类和动物能够通过观察互动,以无监督的方式学习关于世界如何运作的大量背景知识,使机器能够以自监督的方式学习世界模型。
世界模型的结构
由六个独立的模块组成。每个模块都是可微分的,它可以很容易地计算出一些目标函数相对于其自身输入的梯度估计,并将梯度信息传播给上游模块。
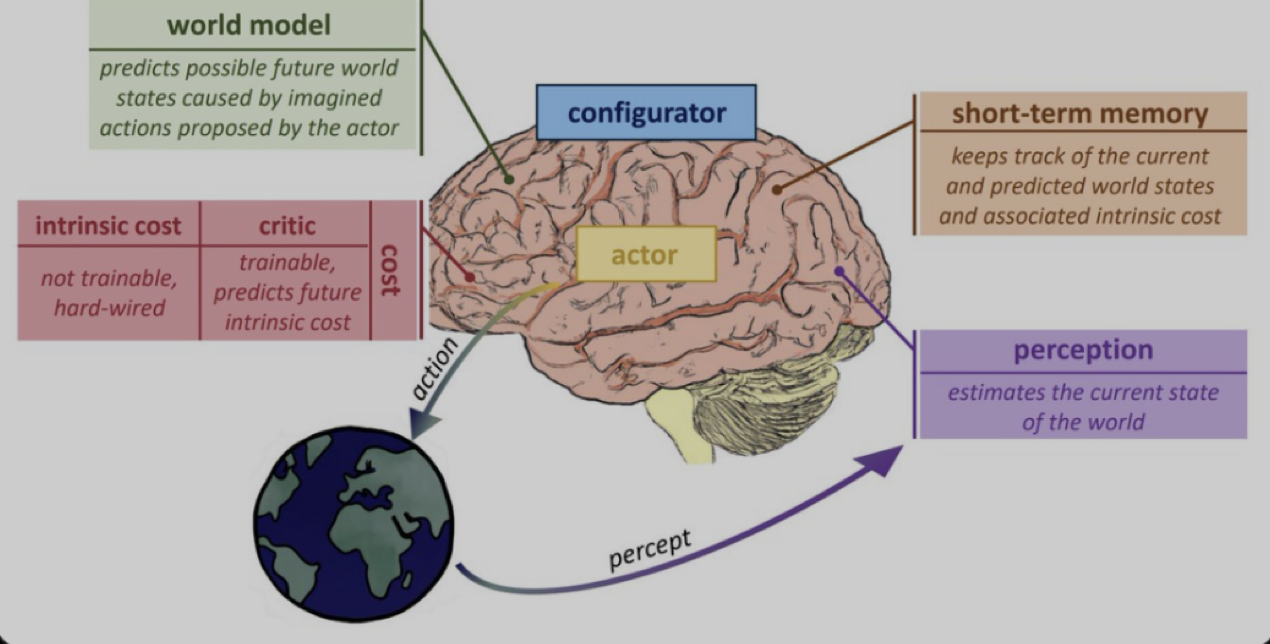
Configurator
配置器模块负责执行控制,给定一个要执行的任务,它会针对这项任务预先配置其它模块
Perception
感知模块接收来自传感器的信号并估计世界当前的状态。提取与当前任务相关的信息。
传感器的信号就是视觉,文字,声音,温度等等信号
World Model
世界模型
评估感知器提取的信息
预测世界的未来状态
训练方法: 对比训练,正则化训练,
eg: JEPA, VICReg
Cost
成本模块
由两个子模块组成:内在成本模块intrinsic cost和批评者模块critic
内在成本模块
不可改变(不可训练)
长期目标是保持内在成本最小化
批评者模块
可训练的模块,预测未来成本
成本的梯度可以通过其他模块反向传播,用于规划、推理或学习。
Actor
行为者模块,计算行动序列的建议
Short-term Memory
短期记忆模块记录了当前和预测的世界状态,以及相关成本。
世界模型的优点
1.什么是无监督,自监督和有监督学习?
- 无监督学习:无监督学习是一种机器学习的类型,它使用未标记的数据来训练模型,即不需要人为地为数据设置标签或目标。在无监督学习中,模型被要求自己发现数据中的模式、结构或特征,以便进行分类、聚类、降维等任务。无监督学习的一个常见应用是聚类,即根据数据的相似性将数据分组。
- 自监督学习:自监督学习是一种无监督学习的形式,其中模型使用数据自身生成的任务进行训练,无需明确的监督。换句话说,数据为训练模型提供了自己的标签。自监督学习的一个常见应用是图像、语音和文本处理,其中模型通过学习数据自身的特性来提取有用的表示。
- 有监督学习:有监督学习是一种机器学习的类型,它使用标记的数据来训练模型,即需要人为地为数据设置标签或目标。在有监督学习中,模型被要求从标记的数据中学习如何进行分类、回归或其他任务。例如,给定一组图像和相应的标注,模型可以学习将新的图像分类到正确的类别中。
2.大语言模型的训练方式和优缺点
以ChatGPT为例,首先使用自监督学习海量基础数据,作为base模型,然后使用有监督学习,即人工准备的问答对作为指令对大模型微调,最后使用了强化学习对模型偏好进行强化。
优点是智能,全面的聊天机器人,但是缺点也很明显,就是自回归模型的随意幻想问题,其次个人觉得现在的大模型持续学习和对话记忆都是有问题的,如果不能对大模型黑盒知识进行定位,那么对模型的优化只能是如今的peft框架或全量微调,对话记忆需要传入全量历史对话。对最大序列长度由很大要求,仍然显得笨重。
此外计算机视觉和多模态的训练时也会图文对的匹配,图片增强后和原始图片对比,或图片的破坏和还原。
3.世界模型的优点
- 学习效率高,无需标注。通过自监督的方式学习,不依赖大量的有监督标注数据,和强化学习的大量实践,主要通过观察的方式学习。观察后的思考即是自监督的学习过程,也是如何设计各种模态进行学习的过程,
- 有状态,Short-term Memory,能够记录连续的事件的状态,相比于大语言模型,不在需要设计超长的context和复杂的prompt
- 具有常识知识后,解决LLM随意幻想的难题。
运作流程
感知–思考(当前信息,短期记忆,常识知识)– 成本 – 行动 – 观察结果 –继续感知
数据被感知模块接收-感知模块处理信号后传递给世界模型-世界模型结合短期记忆和常识知识还有感知模块传递的信息,调用cost模块,估计成本,损失,世界模型根据成本和损失,使用actor采取行动。
结合I-JEPA
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture 论文是第一个对世界模型的常识,代码是https://github.com/gaasher/I-JEPA
I-JEPA分了3个模块,上下文编码器,目标编码器,预测器。
I-JPEA最大的优点是: 不需要数据增强,学习效率更高,是学习的高阶语义,即学习的是一种常识,即世界知识。
上下编码器和目标编码器对应的是Perception,对信号进行有效处理
预测器对应的是World Model,具有常识知识,这里的常识知识就是一种潜变量。
https://zhuanlan.zhihu.com/p/639446627
其它
Salesforce最近也提出了一个Large Action Models的概念,简称LAM。LAM能够自行执行任务的agents,而不是简单地响应人类的查询用户。世界不是一个静态的地方,任何要与之交互的智能体都必须足够灵活,能够优雅地适应环境。LAM具有学习能力,与人类一起工作,人类反馈可用于进一步完善他们的行为。LAM应该具有世界观,知道如何将请求问题转化为一系列步骤,理解连接和围绕这些步骤的逻辑。这意味着理解为什么一个步骤必须在另一步骤之前或之后发生,并知道何时需要改变计划以适应环境的变化。
总结
读万卷书,行万里路。
读万卷书对应着自监督学习,模型自监督的学习效率就是思考的过程。
行万里路对应着强化学习,模型需要通过现实环境的反馈来进行学习。