AIGC之视觉和多模态
一、引言
如下分享的目的主要是为了拓展AIGC方面的思路和视野,谁也没想到最先应用的计算机视觉方向居然被自然语言处理抢了风头,例如目标检测方向的人脸识别和聊天模型Chatgpt,不过未来的模型一定向合并的趋势,即智能的多模态方向发展。
介绍AIGC,介绍视觉,介绍多模态:
AIGC就是人工智能生成内容(Artificial Intelligence Generative Content),也就是让AI自己动手创作各种各样的内容,比如图片、视频、音乐、文字等等。AI:机器模拟人,能够做到看、听、说、想、做。GC:Generated Content,类似用户生成内容(UGC),到专业生成内容(PGC),现在是AIGC,例如,ChatGPT,stable diffusion。
AIGC的视觉代表技术DALL·E,Midjourney,stable diffusion,主要利用扩散模型进行文本生成图像或图像生成图像的技术。
多模态代表多种信号的互相生成和转换,例如根据文本生成音频,视频。给定视频,生成文本摘要信息,根据要求修改视频等。
二、AIGC在视觉任务中的原理和应用
2.1 AIGC-NLP
1)大语言模型LLM用于问答,闲聊和专业问答。
2)用于代码生成,辅助写代码。
发展方向:大模型向Agent的方向和多模态的方向发展了,更智能的话就现在除了堆参数外,模型结构上暂无突破。
2.2 AIGC-CV
1.图片超分辨率: Image Super Resolution
支持多种放大算法: https://www.upscayl.org/

2.上海AI实验室: 利用生成扩散先验实现盲图像恢复
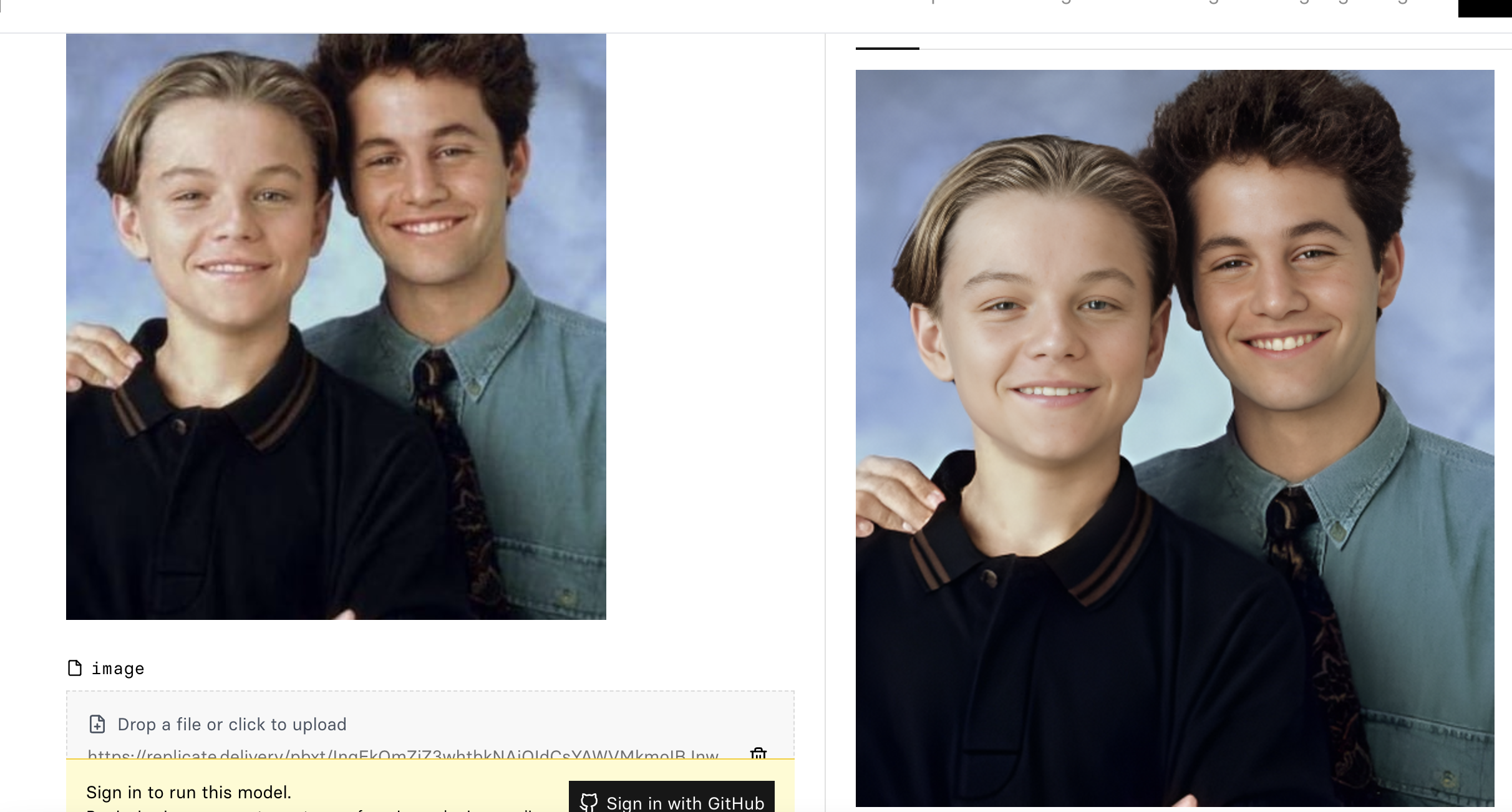
3.针对面部的高清修复: sczhou/codeformer – Run with an API on Replicate
4.针对面部的高清修复, 腾讯GFPGAN
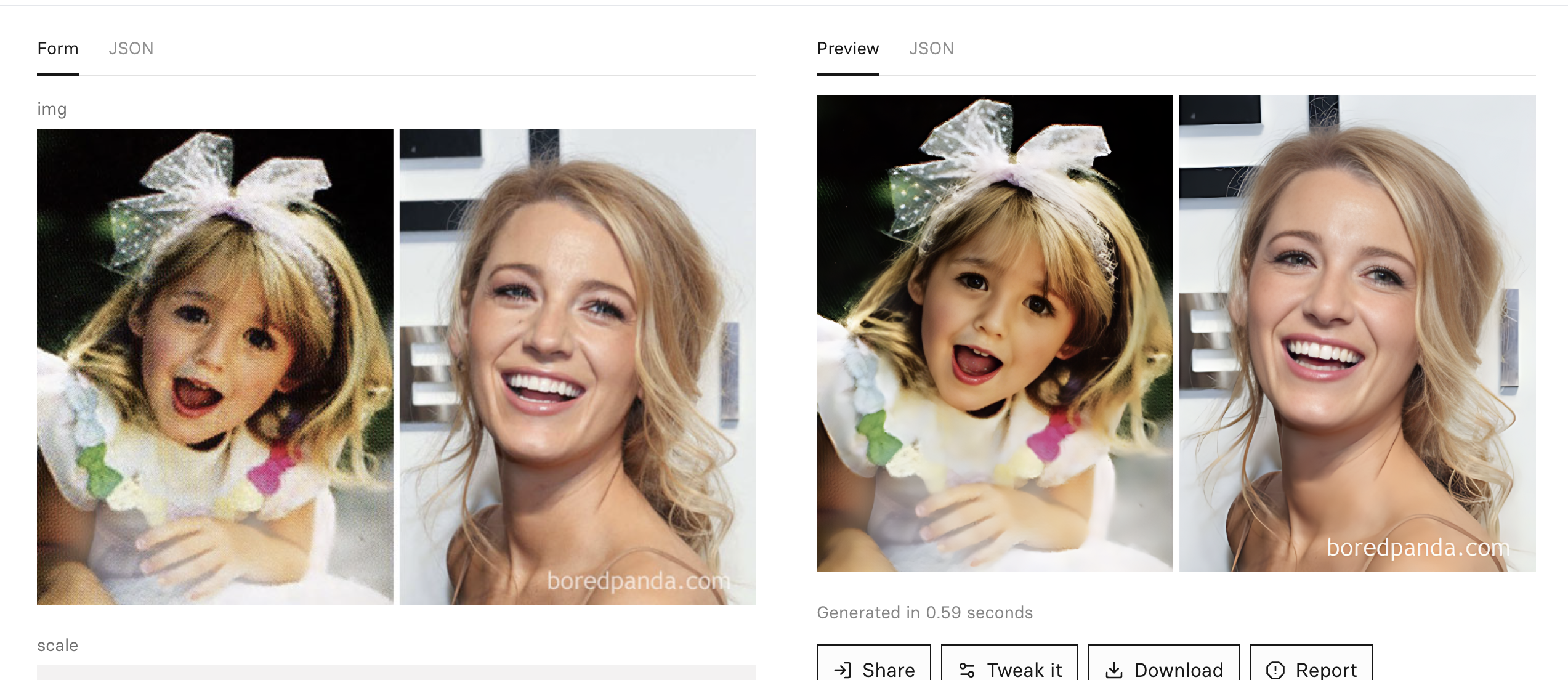
5.图像修复Inpainting和Outpainting
Outpainting是一种利用人工智能技术生成新像素的技术,在不破坏图像原有边界的情况下,无缝地扩展图像。这意味着可以向图像中添加新的细节、扩展背景或创建全景视图,而不会出现明显的接缝或瑕疵。Outpainting技术通过生成视觉连贯和逼真的像素扩展,使图像的构图更加丰富或创造更广阔的视觉背景。
Inpainting是一种利用人工智能技术填补图像缺失部分的技术。当图像中存在缺失、损坏或遮挡时,Inpainting技术可以根据周围的图像信息进行推测和重建,以填补缺失的区域。其目标是使修复后的图像在视觉上保持连贯和自然,使缺失部分与周围环境融合无缝,让人难以察觉修复的痕迹。Inpainting技术在图像修复、恢复古老照片、去除不需要的对象等领域具有广泛的应用。

6.生成修复模型,使用场景的一些参考图像即可实现个性化修复,生成忠实于原始场景的新图:RealFill
7.image editing,根据文字对图片进行修改

Imagic: Text-Based Real Image Editing with Diffusion Models (imagic-editing.github.io)


8.根据提供的参考图像,对目标图像进行编辑。包括物品,人物的外貌修改,形状修改,动作修改等。Picsart-AI-Research/PAIR-Diffusion: PAIR Diffusion: A Comprehensive Multimodal Object-Level Image Editor, 2023 (github.com)](https://github.com/Picsart-AI-Research/PAIR-Diffusion)
修改图像中的物品

9.零样本,适应不同场景,保持纹理细节,同时允许多种局部变化(例如,照明、方向、姿势等),支持对象与不同环境的良好融合。AnyDoor (damo-vilab.github.io)
2.3 AIGC-3D
总结:较为初级。
1.英伟达Magic3D:Magic3D: High-Resolution Text-to-3D Content Creation (nvidia.com)
2.Dream Fusion:
DreamFusion: Text-to-3D using 2D Diffusion (dreamfusion3d.github.io)
一只读书的松鼠:
3.Shape-E:
openai/shap-e: Generate 3D objects conditioned on text or images (github.com)
生成1只鸟:A bird

4.Point-Voxel Diffusion: 点体素扩散(PVD)生成点云,点云在创建逼真的三维模型、场景和动画很有用,对于电影、游戏开发、虚拟现实和增强现实等领域非常重要。在重建真实世界中的物体,自动驾驶和机器人领域也被广泛应用,激光雷达可以生成高分辨率的点云地图,帮助自动驾驶车辆感知和理解周围环境。机器人可以利用点云数据进行环境感知、障碍物检测和路径规划等任务。

5.Linqi (Alex) Zhou — Linqi (Alex) Zhou (alexzhou907.github.io)
6.3D场景渲染,只要根据一个视频就能随时360度渲染其它视觉。新加坡视觉实验室和腾讯开发:HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video (showlab.github.io)
7.OPPO研发的高精度3D重建。NeuRBF: A Neural Fields Representation with Adaptive Radial Basis Functions (oppo-us-research.github.io)
8.苹果研发的增强现实,苹果的VR设备,人物背景视频合成
更多资料:
Wonder3D: Single Image to 3D using Cross-Domain Diffusion (xxlong.site)
https://mrtornado24.github.io/DreamCraft3D/
2.4 AIGC-Video
视频扩散模型(VLDM)
1.图片动起来,从真实视频序列中提取的运动轨迹集合中学习到的模型,例如树木、花朵、蜡烛和在风中摇曳的衣服。2种方式,无缝循环和交互式互动。: Generative Image Dynamics (generative-dynamics.github.io)
2.阿里I2VGen-XL,视频扩散模型(VLDM):https://modelscope.cn/models/damo/Image-to-Video/summary
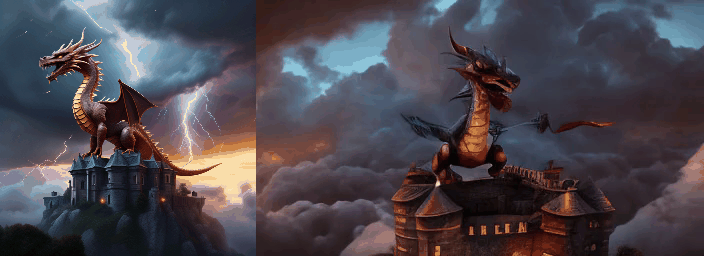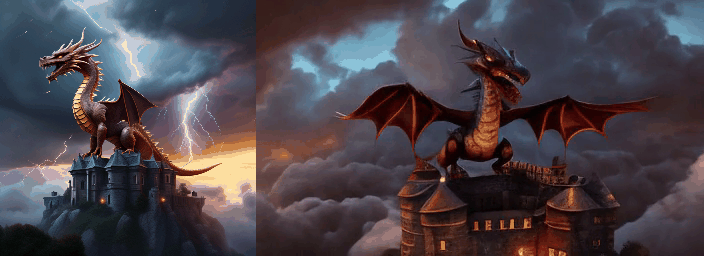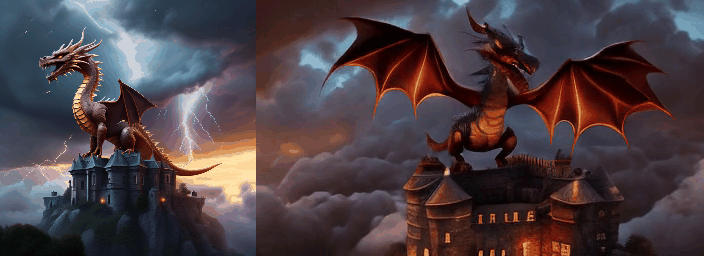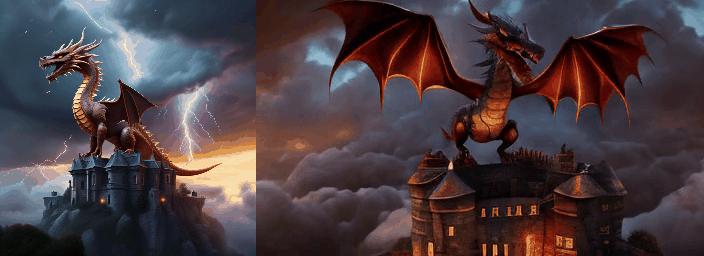
大海,提示如下:
photo of coastline, rocks, storm weather, wind, waves, lightning, 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
4.视频动态修改
根据原始视频和文字对视频进行修改,难点在于视频中事物的时间一致性。
5.效果很好的商业项目:Gen2: Gen-2 by Runway — 跑道 Gen-2 (runwayml.com)
6.视频物体去除:ProPainter for Video Inpainting (shangchenzhou.com)
7.动作捕捉和替换(商业版)
8.视频人物替换(商业版)https://wonderdynamics.com/
9.人物修改(开源版), 可以根据图片,视频,文字,生成新的视频
MagicAvatar: Multi-modal Avatar Generation and Animation (magic-avatar.github.io)
10.人物和场景修改
MagicEdit: High-Fidelity Temporally Coherent Video Editing (magic-edit.github.io)
11.视频中的场景和人物根据参考背景和人物进行替换,下面有具体原理讲解:
12.视频的控制生成
Blockade Labs (@BlockadeLabs) / X (twitter.com)
2.5 Stable diffusion 原理
GAN–>扩散模型–>潜空间扩散模型
2.5.1 GAN: 生成对抗网络,Generative Adversarial Networks, 最初的视觉生成模型。
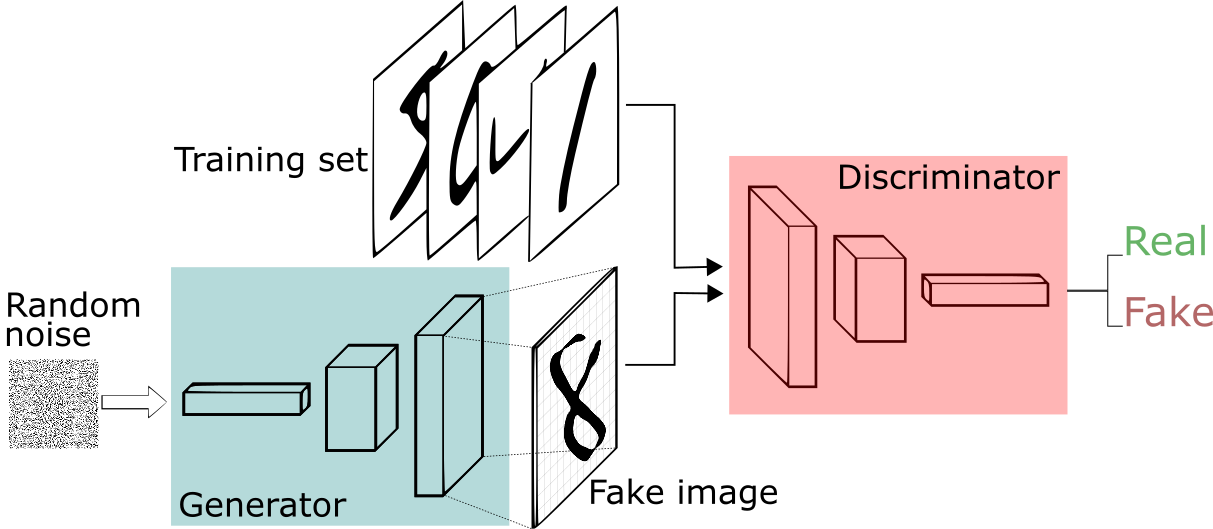
- 定义一个模型来作为生成器(图中蓝色部分Generator),能够输入一个向量,输出手写数字大小的像素图像。
- 定义一个分类器来作为判别器(图中红色部分Discriminator)用来判别图片是真的还是假的(或者说是来自数据集中的还是生成器中生成的),输入为手写图片,输出为判别图片的标签。
生成对抗网络具有如下优缺点:
- 生成对抗网络的生成模型可以生成高质量、逼真的图像、音频等内容;
- 与使用马尔可夫链反复采样的传统生成模型相比,生成对抗网络不需要反复采样,因此它们可以更加高效地处理高维数据;
- 可以采用任何形式的网络结构来学习数据分布的映射关系,无需遵循因式分解模型;
- 训练过程不稳定,容易发生模式崩溃、模式震荡等问题,造成训练中断;
- 由于缺乏预先建模的约束,因此生成的样本可能会出现一些意外的、不可控的情况。
2.5.2 扩散模型原理:
前向扩散过程将噪声添加到训练图像,逐渐将其变成非特征噪声图像。前向处理将把任何猫或狗图像变成噪声图像。反向过程是从噪声图像恢复出真实图像。
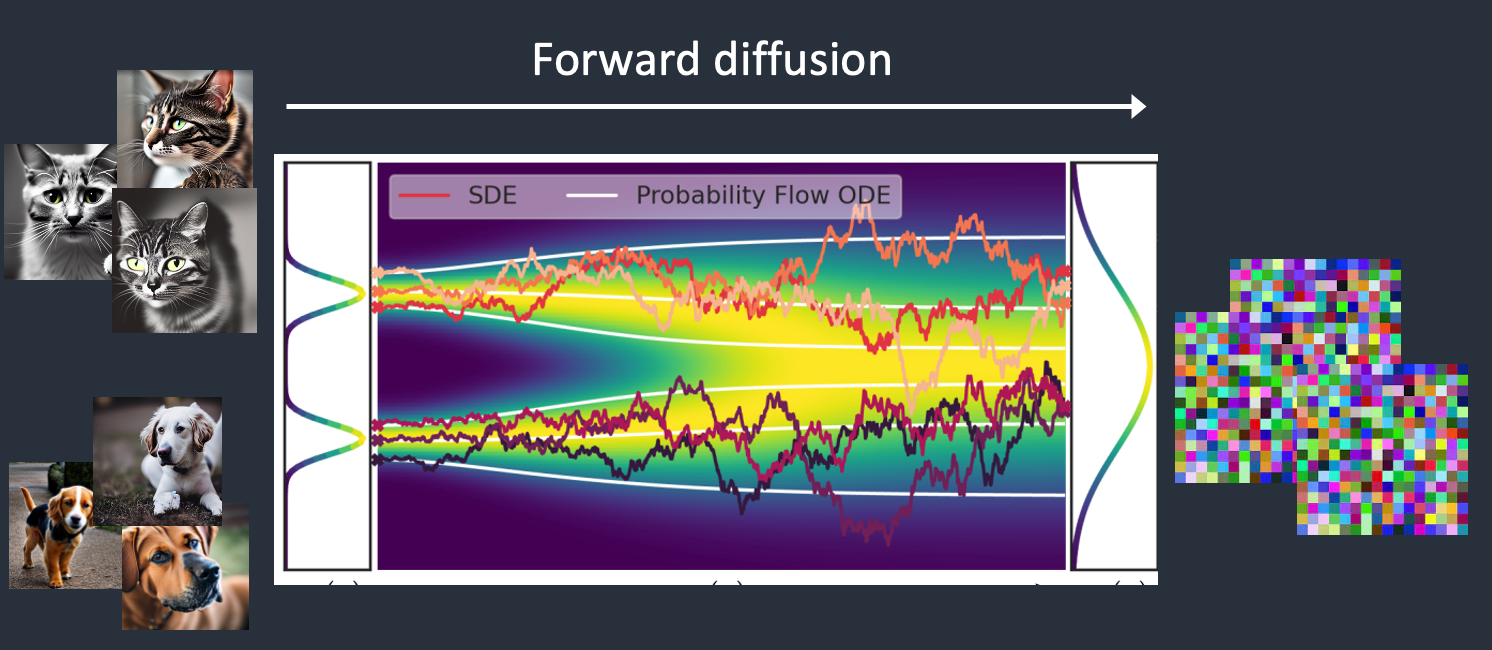
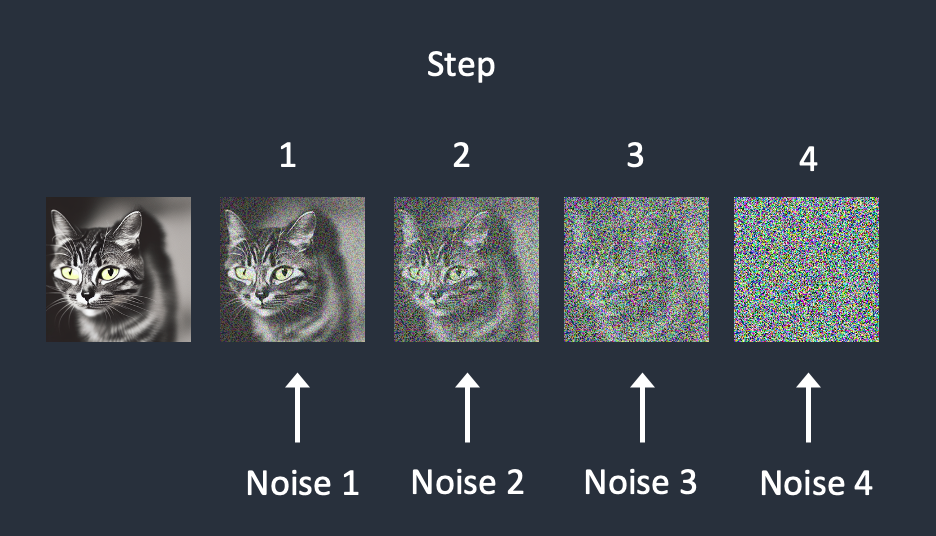
要实现反向扩散,首先需要知道有多少噪声被添加到图像中,前向过程中让模型学习添加的噪声。
1)选择一个训练图像,比如一张猫的照片。
2)生成随机噪声图像。
3)将此噪声图像添加到猫的图片中。
4)噪声预测模型预测添加了多少噪声。
反向过程使用噪声预测模型
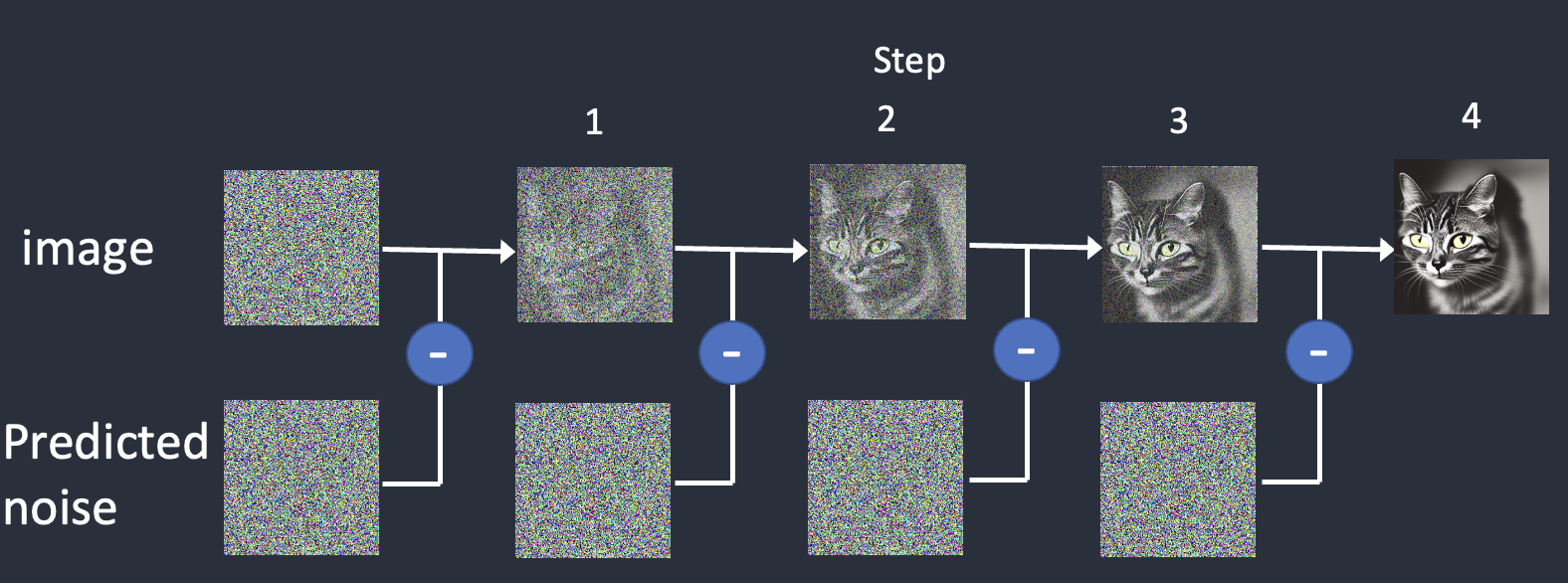
首先生成一个完全随机的图像,并要求噪声预测模型告诉我们噪声。然后我们从原始图像中减去这个估计的噪声。重复这个过程几次。你会得到一个猫或狗的图像。
缺点:不稳定,速度非常慢,需要庞大的step。
2.5.3 VAE Variational Autoencoder 变分自编码器
(1)编码器和(2)解码器。编码器将图像压缩为潜在空间中的较低维表示。解码器从潜在空间恢复图像。
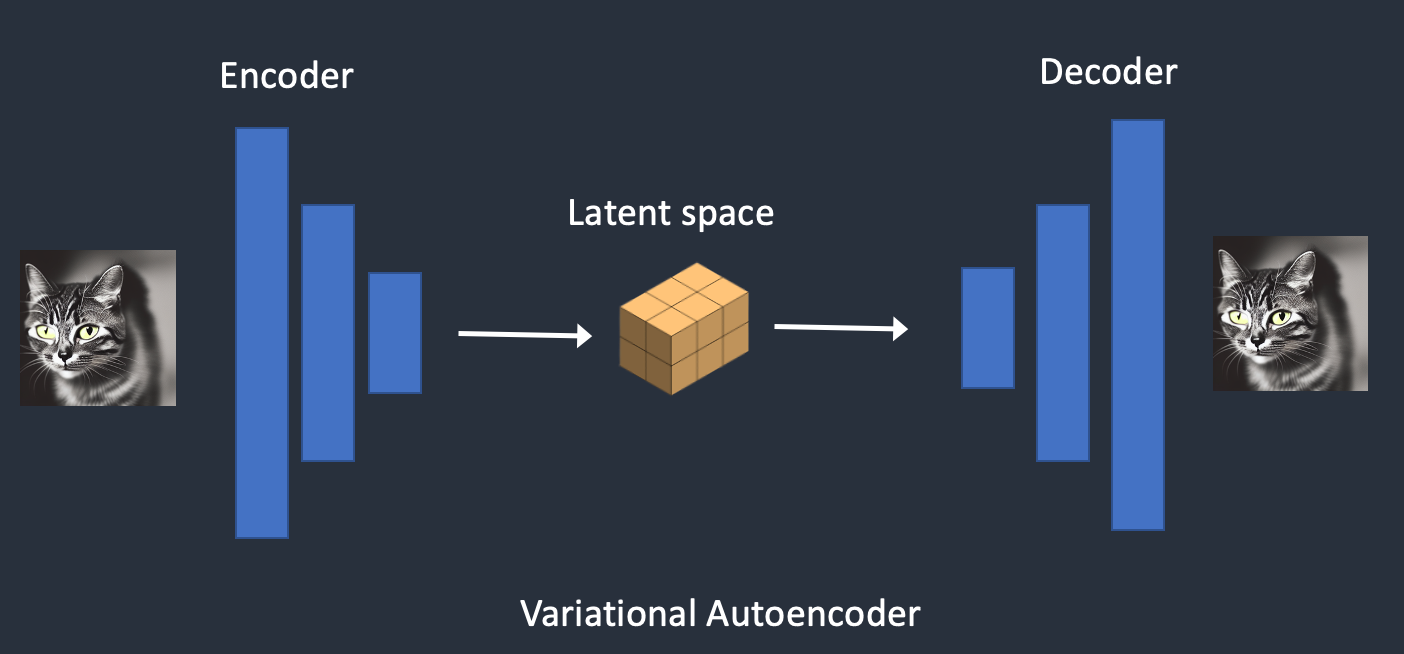
2.5.4 Latent diffusion model 潜扩散模型
利用VAE的特性,对潜空间进行正向和反向扩散的过程。
1)生成随机潜在空间矩阵。
2)噪声预测模型估计潜在矩阵的噪声。
3)然后从潜在矩阵中减去估计的噪声。
4)重复步骤2和3,直到特定的采样步骤。
Tips:
SDXL默认训练图片尺寸是1024x1024, SD1.5是512x512
参考:
https://stable-diffusion-art.com/how-stable-diffusion-work/
https://arxiv.org/abs/2209.00796
2.5.5 UNet, 噪声预测模型
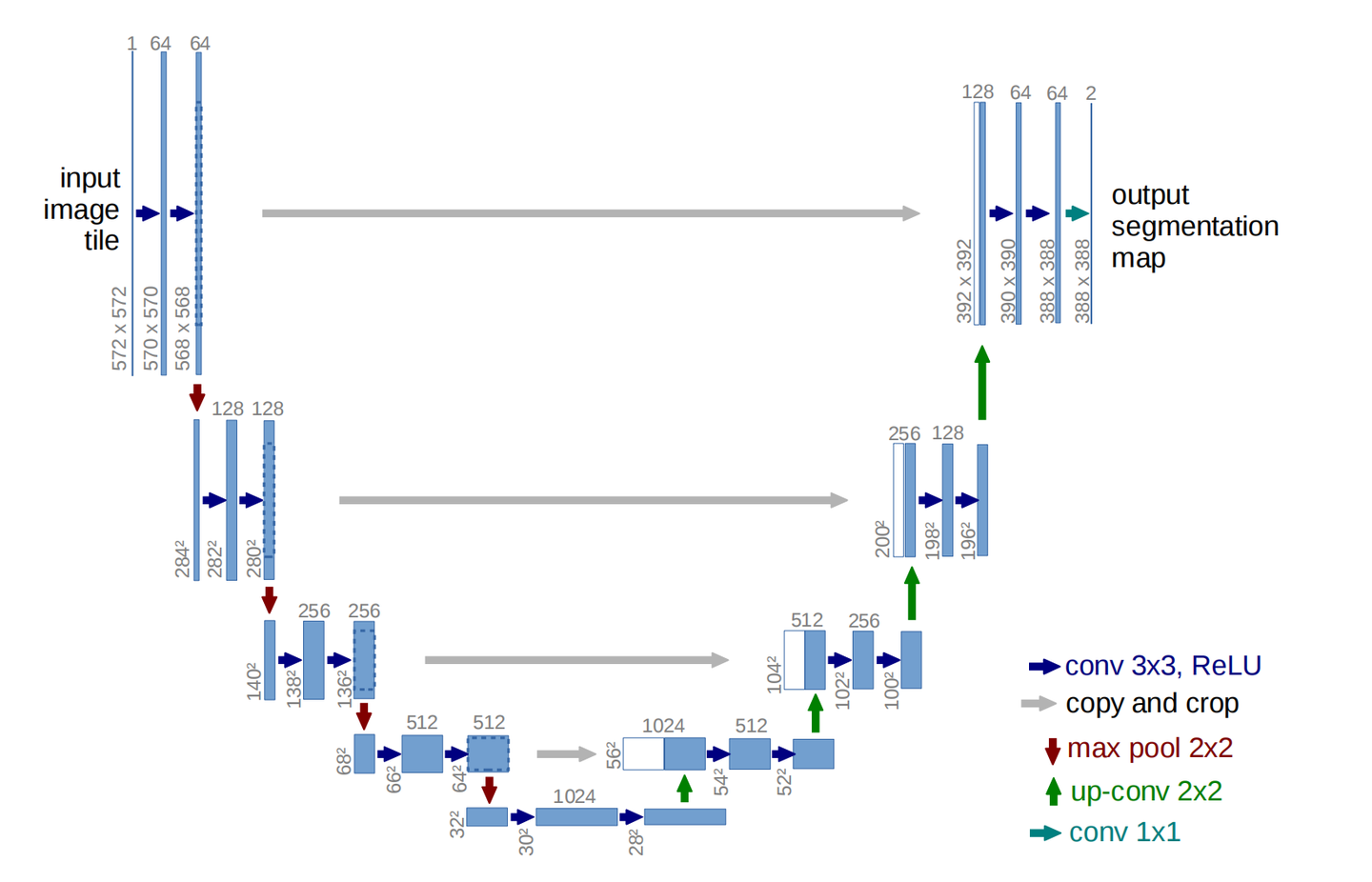
和自动编码器类似,区别是自动编码器的编码器和解码器可以独立使用。但在 UNet 中,解码器与编码器的跳跃连接相连,使用concat加法,编码器在每个上采样步骤为解码器提供有用的信息。
完整的stable-diffusion结构:
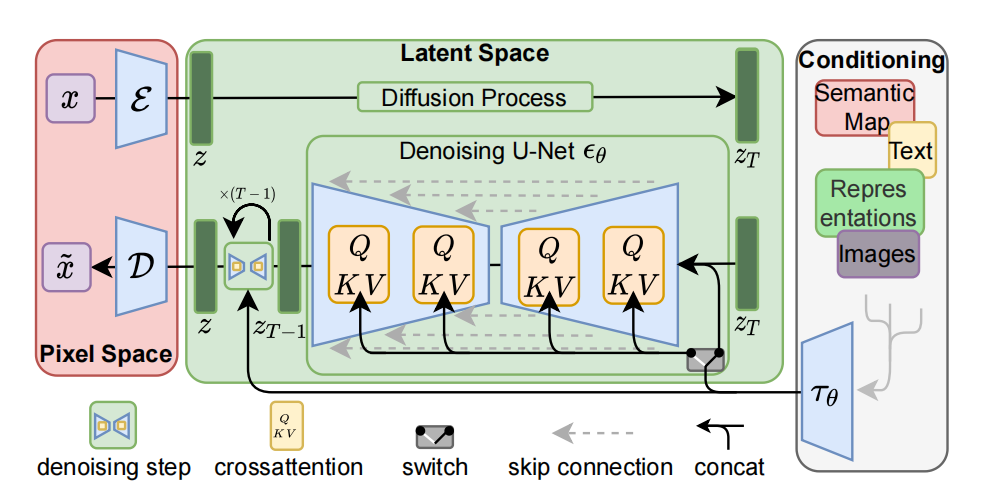
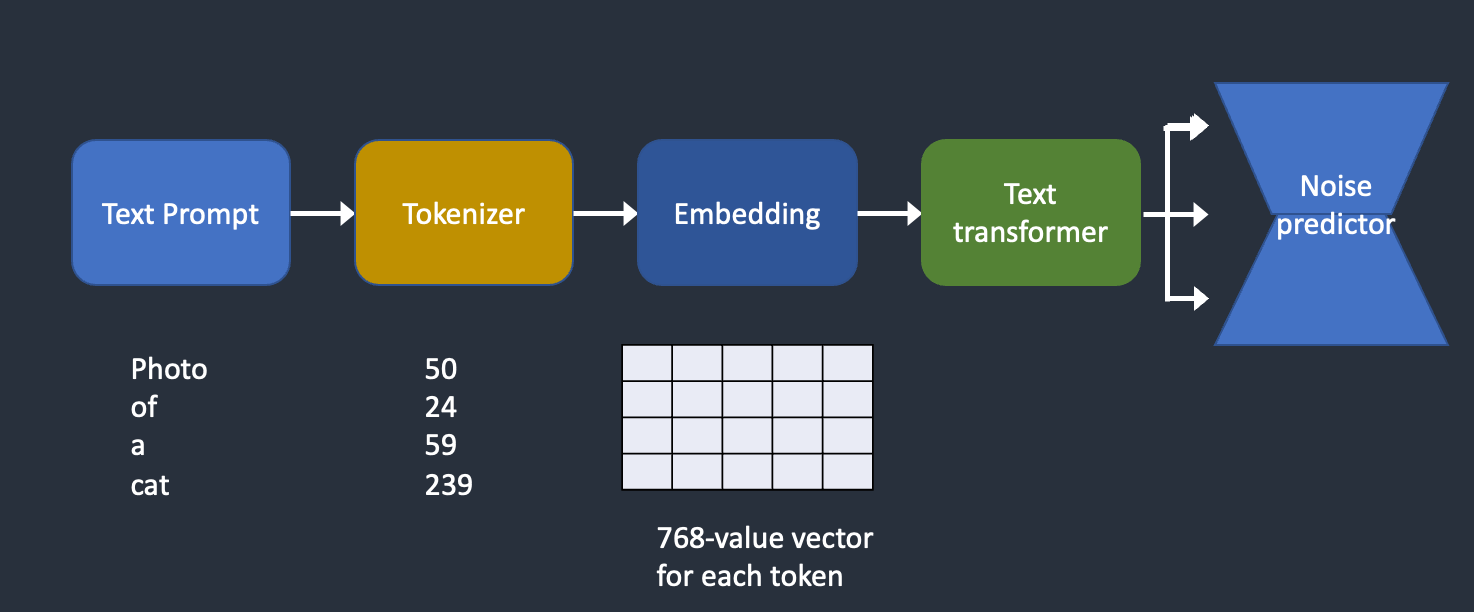
2.5.6 Text conditioning diffusion Model 文本条件扩散模型
CLIP模型:Openai的多模态模型,图像文本对训练,可以图像生成文本描述。这部分生成文本的向量所以是由CLIP模型负责,现在用更好的OpenCLIP代替。
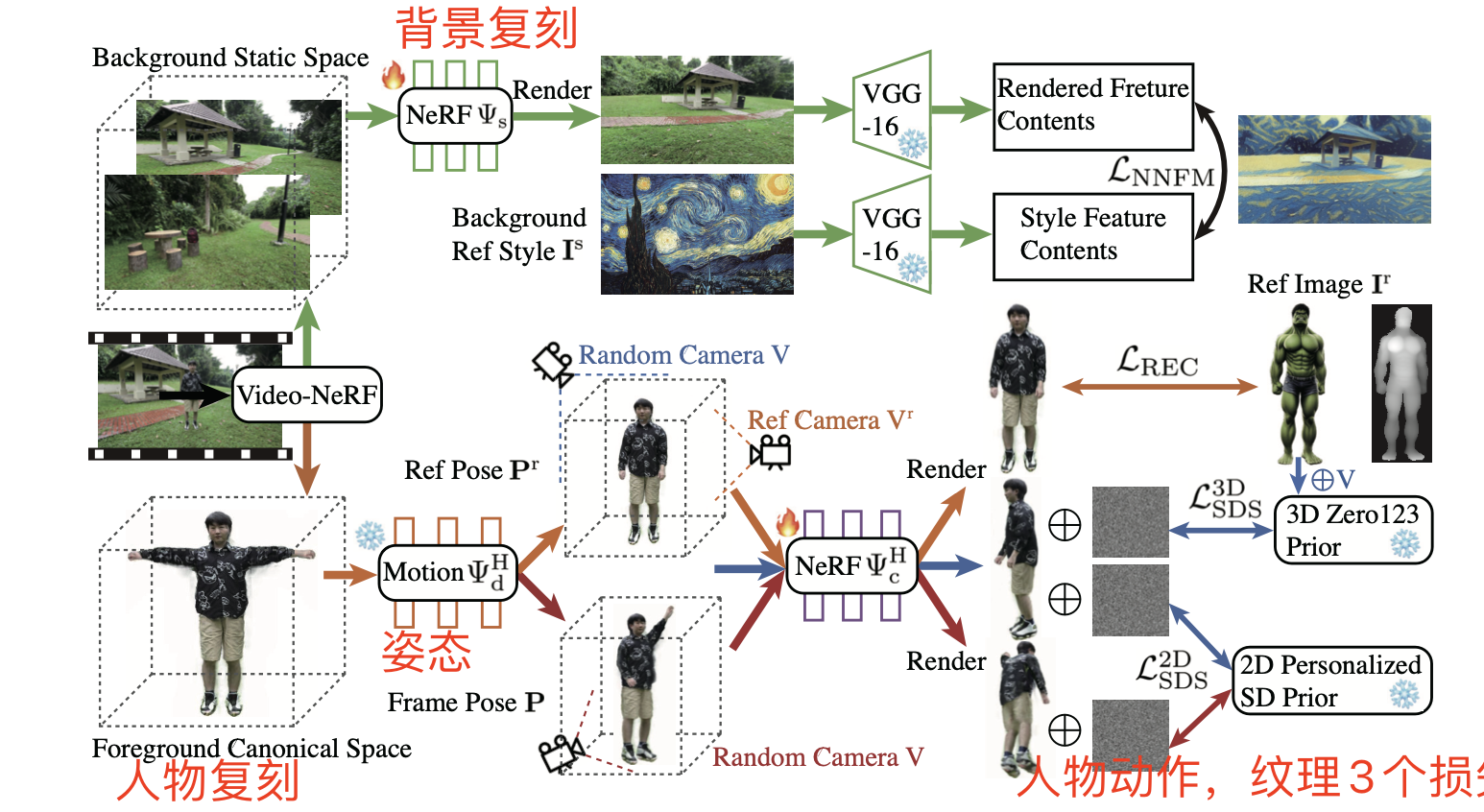
2.6 DynVideo-E 视频修改原理
思考:
有3个要点,1个是背景修改,2是人物修改,3是动作要保持一致
创新点:
- 提出video-NeRF表示来建模动态人体和静态背景
- 使用三维和二维分数蒸馏采样(SDS)来提高三维一致性
- 基于文本的超分辨率放大关键身体区域
- 采用图像风格迁移来编辑三维背景(结构图最上面)
缺点:
该方法只适用于以人为中心的动态视频,如果场景中没有人体,则无法直接应用。后续工作可以考虑扩展到更一般的动态场景。
NeRF:Neural Radiance Fields 神经辐射场,NeRF 的核心思想是将场景表示为神经辐射场,它将三维空间中的每个点映射到颜色和密度值。传统的渲染方法在三维场景中需要建立复杂的模型和纹理映射,而 NeRF 通过学习从观察视角到场景颜色和密度之间的映射关系,可以以更少的数据和先验知识来生成逼真的渲染结果。
$$
F_\theta(\boldsymbol{x}, \boldsymbol{d})=[\sigma, \boldsymbol{c}]
$$
x是空间的坐标x,y,z。d是观察方向,sigma是密度,这里的密度值代表的是光线在改点的终止的概率。c是该点的颜色RGB。NeRF的输入:要生成图像上某点的3D坐标(x,y,z),和观看者的角度, NeRF输出该点的颜色和透明度。
🤔其实所有的生成神经网络都是一个范式,即压缩和还原,压缩是学习事物,学习一种泛化性,压缩到一个潜空间,还原是生成一个原事物或新事物。
SDS: Score Distillation Sampling 分数蒸馏采样 : 由于构建神经半径场(NeRF)所需的数据有限,研究人员开始探索蒸馏方法,以获得与给定文本提示相关的NeRF。Poole等人的开创性工作 提出了一种称为分数蒸馏采样(SDS)的方法,将2D文本到图像扩散模型蒸馏成3D NeRF。与传统的NeRF构建方法不同,传统方法需要目标3D物体的多个视角图像,而基于文本的NeRF构建缺少了3D物体和多个视角图像。SDS方法通过最小化固定视角下NeRF生成的图像与扩散模型的损失函数来优化NeRF。为了避免直接优化扩散模型的损失函数所带来的计算开销,研究人员提出通过省略Unet雅可比项来近似蒸馏目标。
三、AIGC在多模态任务中的原理和应用
介绍多模态问答,声音生成
3.1 AIGC-QA 多模态问答
GPT-4 (all-Tools)
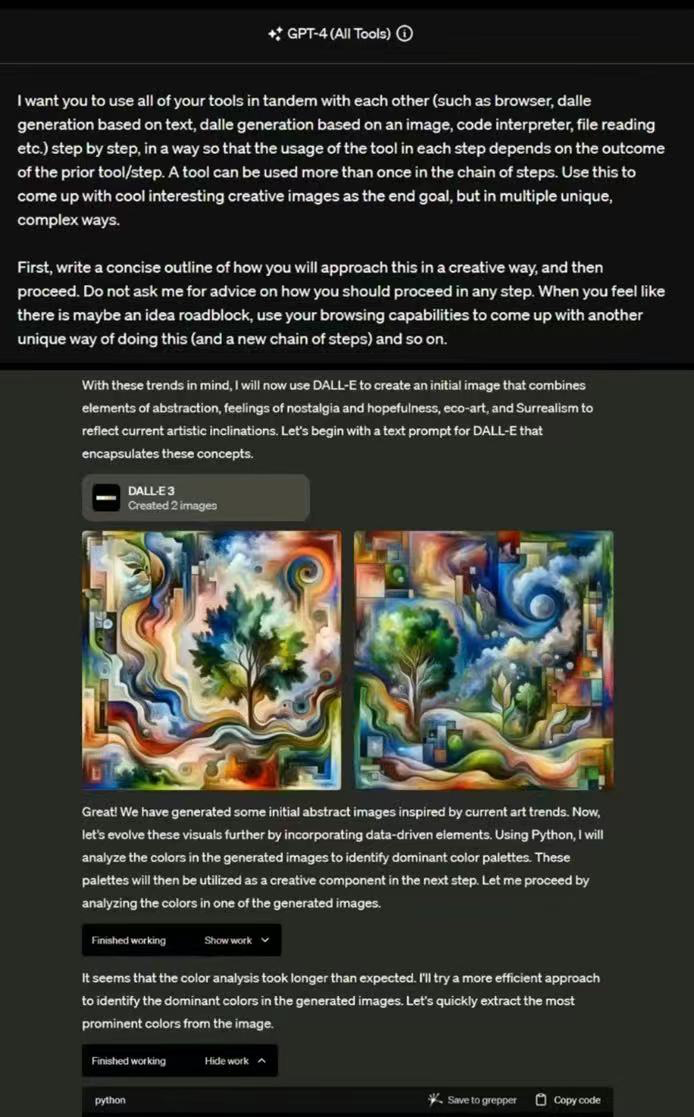
更多资料:
De-Diffusion (dediffusion.github.io)
3.2 AIGC-Audio
Meta的seamless-m4t: Introducing a foundational multimodal model for speech translation — 引入语音翻译的基础多模态模型 (meta.com)
视频声音翻译加音色转换
HeyGen - AI Spokesperson Video Creator
类似HeyGen的工具, AI Dubbing: Translate Video and Voice with the Best Voiceover Tool (elevenlabs.io)
生成音乐: Stable Audio - Generative AI for music & sound fx
Trance, Ibiza, Beach, Sun, 4 AM, Progressive, Synthesizer, 909, Dramatic Chords, Choir, Euphoric, Nostalgic, Dynamic, Flowing
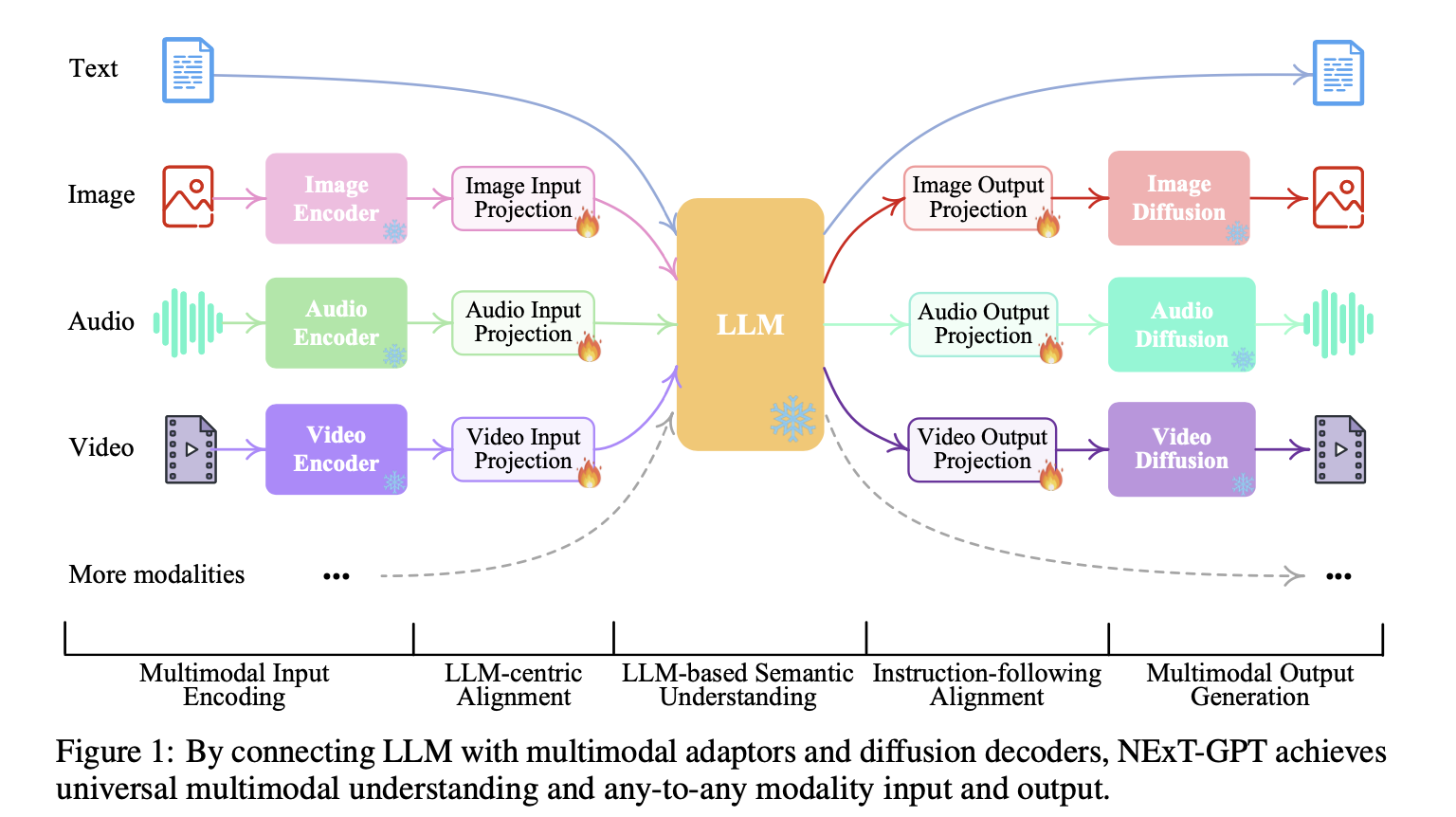
3.3 Next-GPT原理
作用:模拟人的多模态感知和输出能力,超越GPT4的多模态聊天。
优点:接收文本,图像,视频,音频的任意组合,并输出它们,只微调已训练过模型的投影层,训练量小,扩展性高,灵活更换更多模型和模态
缺点:中文一般,有时不能按指令生成图片,音频和视频,可能模态指令转换数据集不全面引起的,导致不能生成其它模态的token
原理: 以大语言模型为核心,不同模态的编码器作为输入,解码器作为输出。中间用投影层作为胶水黏合,只需要对投影层进行微调
结构:
编码阶段:
利用现有的各个模态的编码器对各种模态的输入进行编码,然后通过投影层将这些表示投影到 LLM 可理解的类语言表示中。
使用Meta的ImageBind模型
LLM理解和推理阶段:
利用现有的开源 LLM 作为核心,处理输入信息以进行语义理解和推理。LLM 不仅能直接生成文本token,还能生成独特的 “模态信号 “token,作为指令表明解码层是否要输出相应的模态内容
使用Vicuna2
输出
1)直接的文本响应
2)每种模态的信号token
这些信号token作为指令表明解码层是否生成多模态内容,以及如果生成则生成什么内容。
解码阶段:
产生的带有特定指令的多模态信号经过投射后,会进入不同的编码器,最终生成相应模态的内容。
图像模型stable diffusion,视频合成的 Zeroscope,音频合成的 AudioLDM
四、在线试用
聊天:
https://chatglm.cn/main/detail
https://www.baichuan-ai.com/home
https://yiyan.baidu.com/welcome
文生图:
https://jsai.cc/ai-muses/gallery
五、结论
AIGC在视觉和多模态方向经历了从GAN到VAE再到扩散模型的发展过程。在视觉方面,GAN的生成效果好但训练不稳定,扩散模型克服了这一缺点,得到了更好的生成效果。随着VAE的引入,扩散模型在潜空间中进行,生成更稳定。文本提示的引入使得扩散模型可以进行条件图像生成。在多模态方面,大语言模型的应用让不同模态之间的转换成为可能,诸如图片到文本,文本到语音等。下一步的挑战是实现真正的多模态一体化,不同模态之间无缝转换。在视觉方面,需要处理更复杂的三维场景;在多模态方面,需要处理不同模态之间的语义一致性。未来预计会看到基于transformer的统一多模态模型的出现,实现任意模态之间的转换。总体来说,AIGC在视觉和多模态方向拓展了计算机的感知和表达能力,朝着模拟人类智能的方向前进,但仍需进一步的研究来克服现有的局限,实现真正的通用人工智能。
AIGC的多模态未来充满想象空间,随着计算能力、数据和算法的发展,我觉得超越人类的智能不远了。