训练1个LLM做情感分析
一、目的
预测食品领域数据的情感
二、要求
一共是13个维度:包装,便捷程度,场景,服务,价格,口感,烹饪方法,皮,气味,外形,馅料,质量缺陷
给出评论,库中对应的商品名称,已经和评论强制匹配,给出维度和匹配的关键词,判断给定词语的情感
三、方案
方案1:基于用户给定的主体和关键词,只预测情感
Prompt
你是一个情感分析抽取模型,请根据评论提取其中的情感关系四元组。
13种关系包括包装,便捷程度,场景,服务,价格,口感,味道, 烹饪方法,皮,气味,外形,馅料,质量缺陷,每种的主要包括的
维度是
皮包括皮原料,皮厚度,软硬度,弹韧度,清爽度,粗细度,耐烹饪性,皮喜好度等
馅料包括馅配料,馅料量,馅料新鲜度,馅料紧实度,馅料拉丝度,馅料添加剂,馅料安全度,馅料喜好度等
口感包括口感喜好度,口感细节,汁水等
味道包括味道喜好度,味道感受,鲜美度,甜度,咸度,辣度,酸度,味道浓淡,具体味道等
气味包括气味感受,具体气味,气味喜好度等
外形包括个头,饱满度,外观,紧实度,破损度,外形喜好度等
烹饪方法包括烹饪方法词等
质量缺陷包括吃出异物,食品腐坏,有异味,食用后不良反应,日期不新鲜,包装胀气等
便捷程度包括便捷相关词语等
场景包括用餐时间,节假时节,用餐人数,具体情境,健康宣称,用餐搭配,情绪价值等
包装包括包装设计外观,密封性,取用难易度,可持续性,存放难易度,包装托盒,包装质量等
服务包括客服,售后,配送,物流包装等
价格包括价格合理度,比价,价格变动,性价比等
每个四元组应该包括主体(食物名称,已给出)、关系(13种的一种,已经给出),客体(评论中具体描述词语,已经给出),主客体情感
(积极,消极,中性,3种的一种,需要预测)。答案中需要补全主客体情感,
评论是:{question},
需要预测的是,问号部分需要预测: {entities},
输出格式是:
(主体,关系,客体,主客体情感)
(主体,关系,客体,主客体情感)
例如预测的entities
(千层糕,烹饪方法,蒸,??)
(千层糕,场景,早餐,??)
(千层糕,场景,日常,??),
优点:给出了详细的prompt,只有情感位置是问号标注的,那样模型可变动的信息更少,结果更稳定
缺点
方案的缺点是数据处理人员已经给出主体和关键词实体,主体和关键词实体是基于正则匹配的,会有很多错误,这影响了情感的判断。
方案2:LLM直接生成主体,关键词,维度和情感
prompt
你是一个情感分析抽取模型,请根据评论提取其中的情感关系四元组。
13种关系包括包装,便捷程度,场景,服务,价格,口感,味道, 烹饪方法,皮,气味,外形,馅料,质量缺陷,每种的主要包括的
维度是
皮包括皮原料,皮厚度,软硬度,弹韧度,清爽度,粗细度,耐烹饪性,皮喜好度等
馅料包括馅配料,馅料量,馅料新鲜度,馅料紧实度,馅料拉丝度,馅料添加剂,馅料安全度,馅料喜好度等
口感包括口感喜好度,口感细节,汁水等
味道包括味道喜好度,味道感受,鲜美度,甜度,咸度,辣度,酸度,味道浓淡,具体味道等
气味包括气味感受,具体气味,气味喜好度等
外形包括个头,饱满度,外观,紧实度,破损度,外形喜好度等
烹饪方法包括烹饪方法词等
质量缺陷包括吃出异物,食品腐坏,有异味,食用后不良反应,日期不新鲜,包装胀气等
便捷程度包括便捷相关词语等
场景包括用餐时间,节假时节,用餐人数,具体情境,健康宣称,用餐搭配,情绪价值等
包装包括包装设计外观,密封性,取用难易度,可持续性,存放难易度,包装托盒,包装质量等
服务包括客服,售后,配送,物流包装等
价格包括价格合理度,比价,价格变动,性价比等
每个四元组应该包括主体(食物名称)、关系(13种的一种,评论最后已经给出),客体(评论中具体描述词语,评论最后已经给出),主
客体情感(积极,消极,中性,3种的一种)。
答案中至少包含给出的关系和客体,并补全主体和主客体情感,评论是:<{question}>
请按照以下格式提取关系四元组列表,无需多余解释。
(主体,关系,客体,主客体情感)
(主体,关系,客体,主客体情感)
优缺点
因为依靠模型生成了所有的主体,关系和客体,情感,所以需要更多的数据训练,才能保证我们模型预测的范围在我们需要的词语范围內,主体,关键词相对准确一些。最后筛选阶段,可以按需筛选需要的数据。也防止了规则打标匹配时的大量无效数据。
方案3:简单版
prompt
你是一个情感分析抽取模型,请根据评论提取其中的情感关系四元组。每个四元组应该包括主体(食物名称)、关系(包装,便捷程度,场景,服务,价格,口感,烹饪方法,皮,气味,外形,馅料,质量缺陷,13种的一种),客体(评论中具体描述词语,主客体情感(积极,消极,中性,3种的一种)。一定要尽可能找全
所有的关系。
评论是:<{question}>
请按照以下格式提取关系四元组列表,无需多余解释。
(主体,关系,客体,主客体情感)
(主体,关系,客体,主客体情感)
如果整个评论没有可识别的关系或者不是用户评论,请返回”无”。
优缺点
可以方便开始阶段数据人员扩充数据字典
方案4:基于训练好的LLM,生成更多样本,然后对应训练小模型,使得预测速度更快。
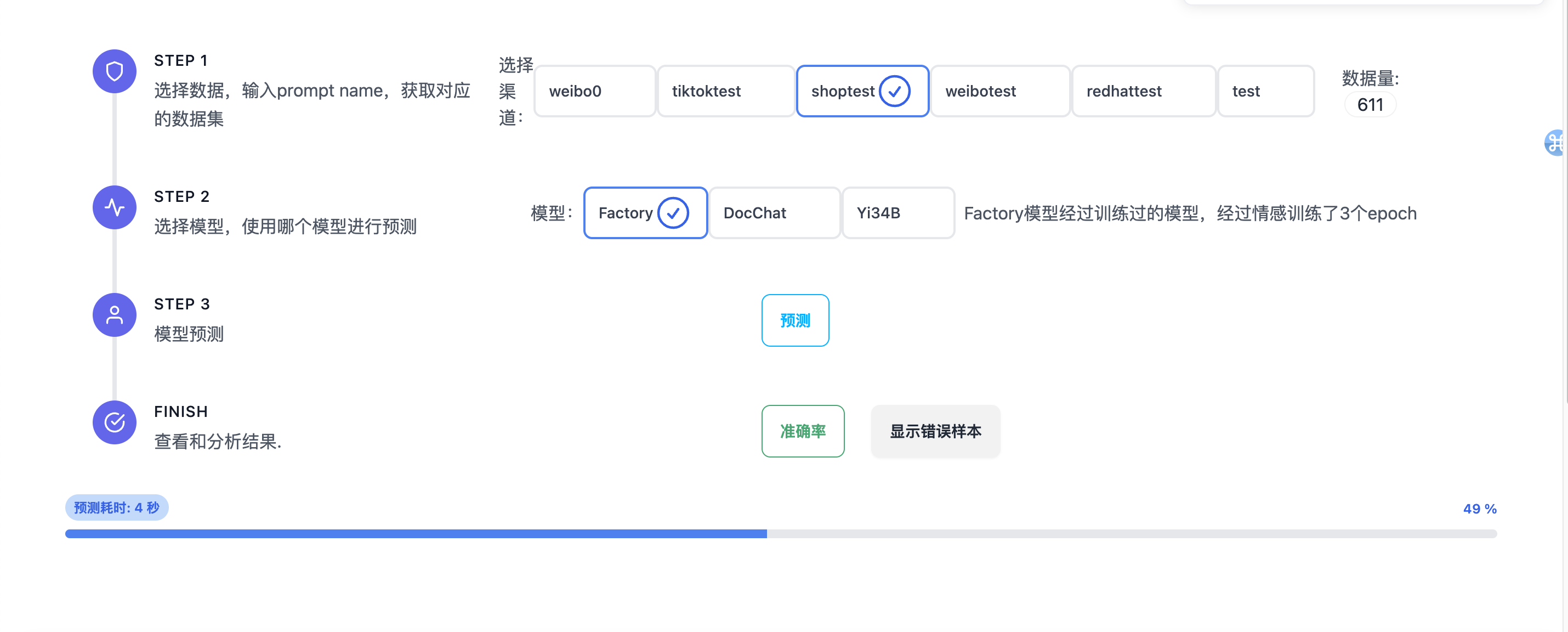
四、数据标注
1.设置要标注的数据集

这里我们可以让每个用户选则自己需要的数据集
2.开始标注,自动采样一条数据,然后使用未经训练的模型进行辅助预测,我们后来经过测试,未经过训练的LLM模型的准确率有52%左右。

3.点击添加,点击情感都可以进行对数据进行修改,保存数据。

4.查看数据。
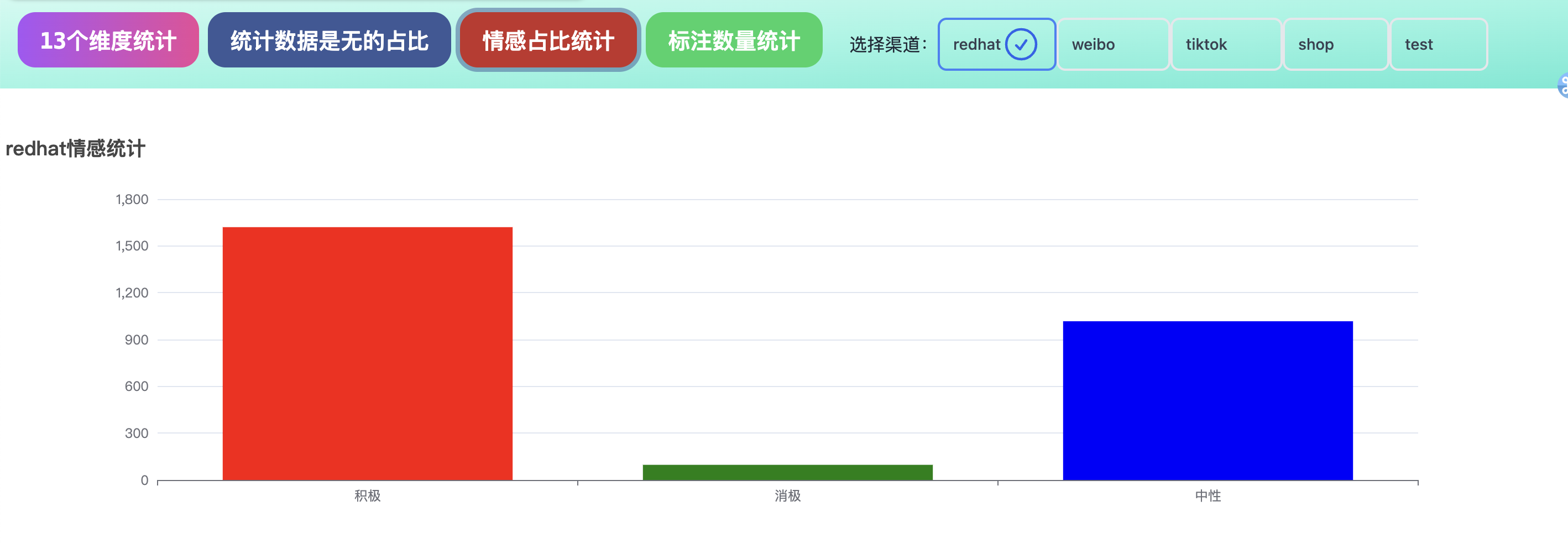
4.查看数据的统计结果,每个维度的数据统计。发现数据不同渠道,数据存在不均衡问题。
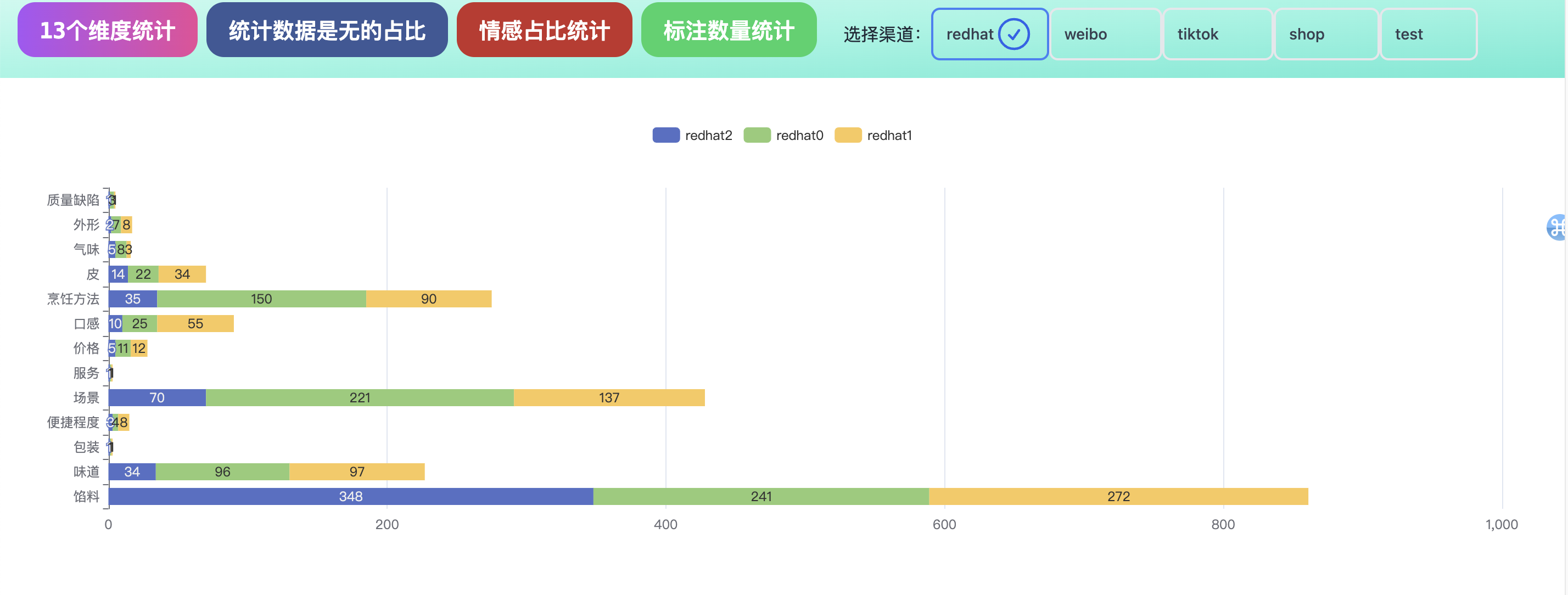
查看数据的情感标签,发现同样存在不均衡问题。
五、模型训练
我们使用Llama-Factory训练了3个epoch, 使用Qwen7B-Chat作为base模型,发现loss下降很快。更多epoch待测试。
六、模型测试
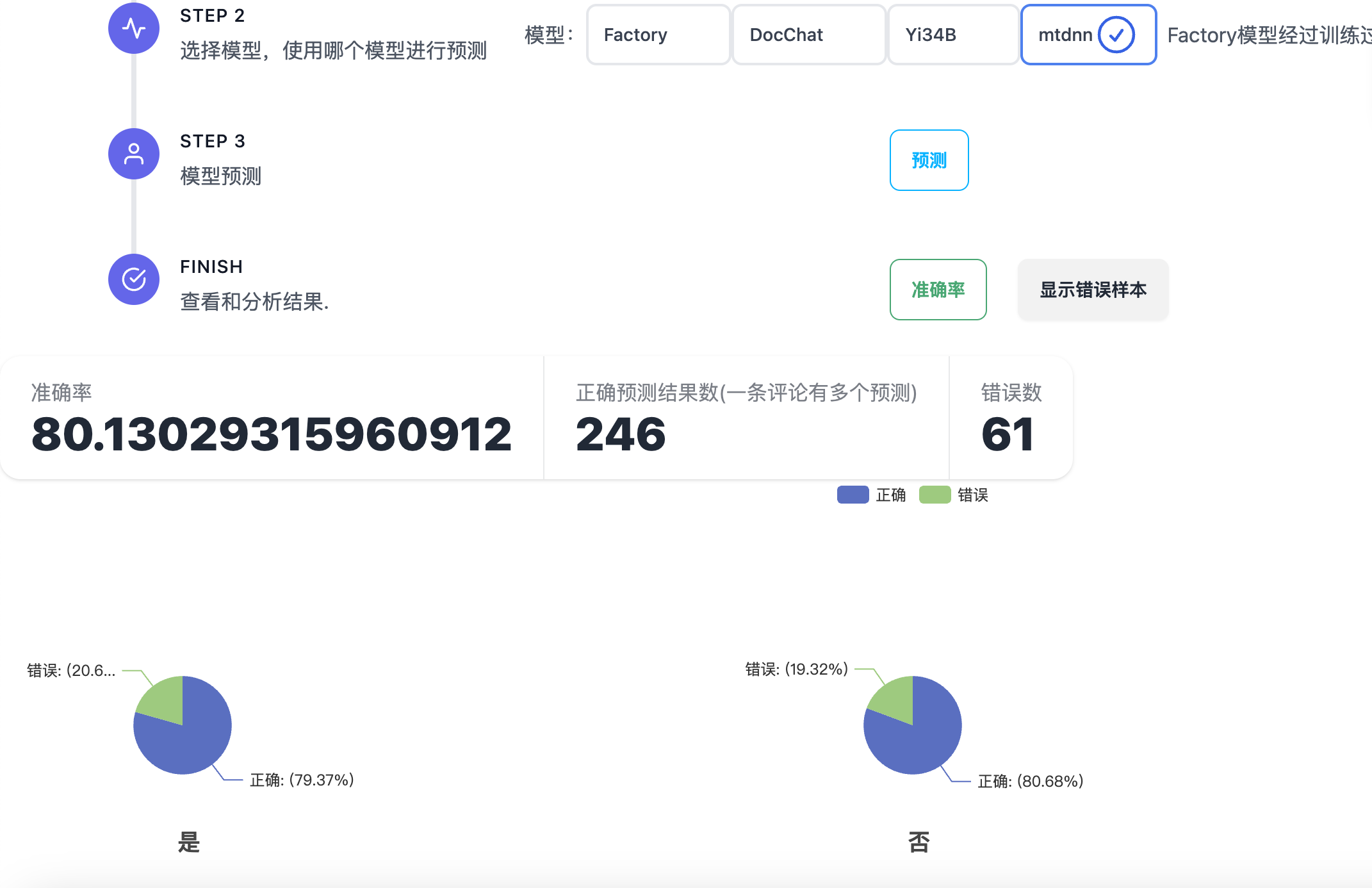
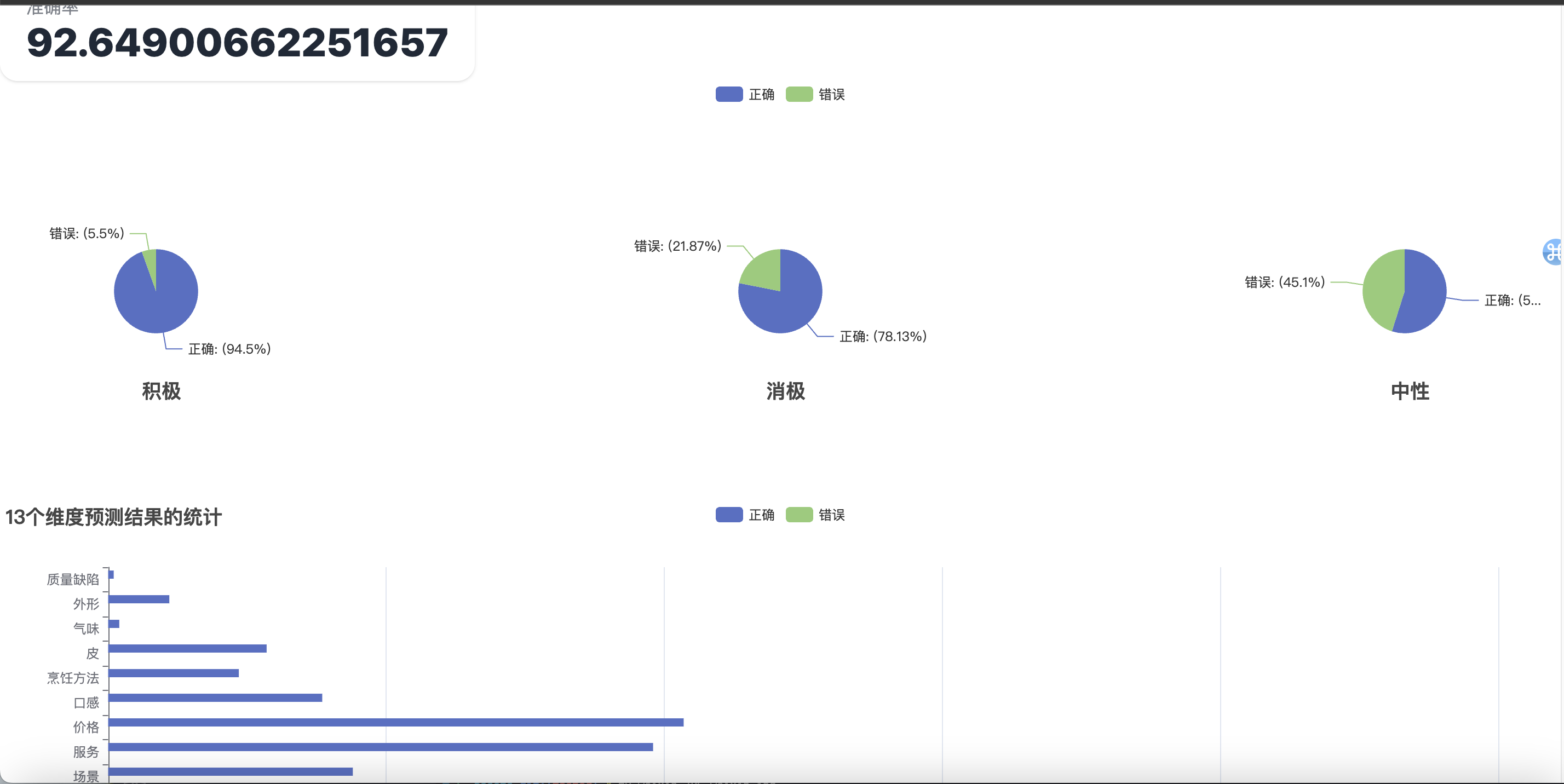
对测试集进行测试
统计每个情感属性和每个维度属性的预测结果和准确率,大部分错误集中在中性和积极混淆,这是符合常识的。
观察错误样本:

七、经验总结
我们发现使用Lora 训练的Qwen7B大模型要好于mtdnn训练的小模型,在测试情感分析和13个维度的实体判断方面,准确率分别有哦4%和5%的提升,但是预测速度相差很大。
大模型:
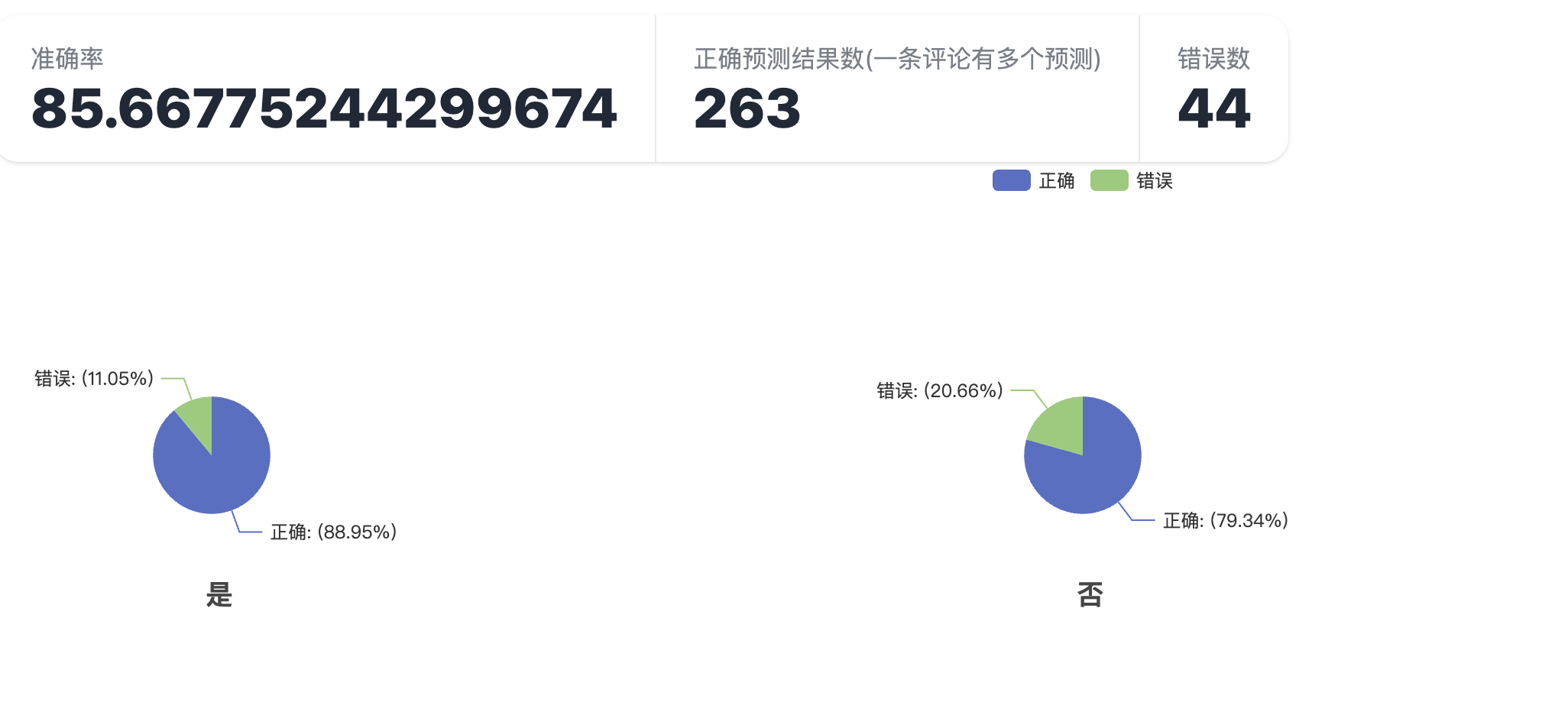
小模型: